해시 테이블
Hash table| 해시 테이블 | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 유형 | 순서 없는 연관 배열 | ||||||||||||||||||||
| 발명된 | 1953 | ||||||||||||||||||||
| 빅 O 표기의 시간 복잡도 | |||||||||||||||||||||
| |||||||||||||||||||||
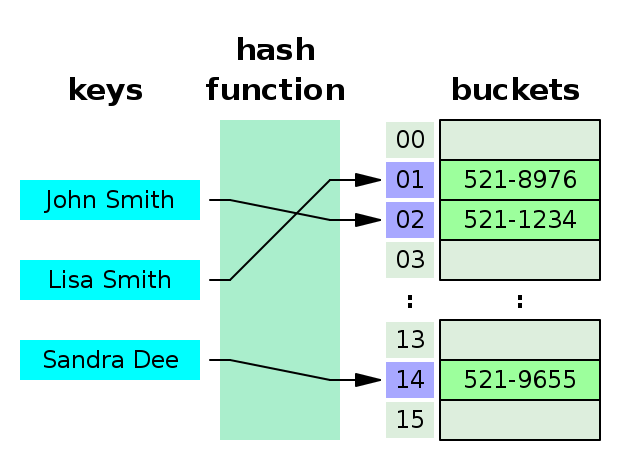
컴퓨팅에서 해시 맵 또는 사전으로도 알려진 해시 테이블은 키에 값을 매핑할 수 있는 구조인 집합 추상 데이터 유형을 구현하는 데이터 구조입니다.해시 테이블은 해시 함수를 사용하여 원하는 값을 찾을 수 있는 버킷 또는 슬롯 배열로 인덱스를 계산합니다.조회 중에 키가 해시되고 결과 해시는 대응하는 값이 저장되어 있는 위치를 나타냅니다.
해시 함수는 각 키를 하나의 버킷에 할당하는 것이 이상적이지만 대부분의 해시 테이블 설계에서는 불완전한 해시 함수를 사용합니다.이 때문에 해시 함수가 여러 키에 대해 동일한 인덱스를 생성하는 해시 충돌이 발생할 수 있습니다.그러한 충돌은 일반적으로 어떤 식으로든 수용된다.
고차원 해시 테이블에서 각 룩업의 평균 시간 복잡도는 테이블에 저장되어 있는 요소의 수에 의존하지 않는다.또한 많은 해시 테이블 설계에서는 키-값 쌍을 상각된 [2][3][4]작업당 일정한 평균 비용으로 임의로 삽입 및 삭제할 수 있습니다.
해시는 시공간의 트레이드오프의 한 예입니다.메모리가 무한대인 경우 키 전체를 인덱스로 직접 사용하여 단일 메모리 액세스로 값을 찾을 수 있습니다.한편, 무한대의 시간을 사용할 수 있는 경우는, 키에 관계없이 값을 보존할 수 있어 바이너리 검색이나 선형 검색을 사용해 [5]: 458 요소를 검색할 수 있습니다.
대부분의 경우 해시 테이블은 검색 트리나 다른 테이블 검색 구조보다 평균적으로 더 효율적입니다.이러한 이유로 특히 연관 배열, 데이터베이스 인덱싱, 캐시 및 세트 등 다양한 종류의 컴퓨터 소프트웨어에 널리 사용됩니다.
역사
해시에 대한 생각은 다른 장소에서 독립적으로 일어났다.1953년 1월, Hans Peter Luhn은 체인과 해싱을 사용하는 IBM 내부 메모를 작성했습니다.오픈 어드레싱은 나중에 Luhn의 논문에서 A.[6]: 15 D. Linh 빌딩에 의해 제안되었다.비슷한 시기에 IBM Research의 Gene Amdahl, Elaine M. McGraw, Nathaniel Rochester 및 Arthur Samuel은 IBM 701 어셈블러를 [7]: 124 위해 해시를 구현했습니다.선형 프로브를 사용한 오픈 어드레싱은 Amdahl에 의한 것으로 인정되지만, Ershov는 독립적으로 같은 생각을 [7]: 124–125 가지고 있었습니다."오픈 어드레싱"이라는 용어는 W에 의해 만들어졌습니다. Wesley Peterson은 큰 [6]: 15 파일 검색의 문제를 논하는 그의 기사에 있습니다.
체인을 이용한 해시에 관한 첫 번째 연구는 나머지 모듈 프라임을 해시 [6]: 15 함수로 사용하는 아이디어를 논의한 Arnold Dumey의 공로를 인정받았다.해싱이라는 단어는 로버트 [7]: 126 모리스의 기사에 의해 처음 출판되었다.선형 탐침의 이론적 분석은 원래 Konheim과 [6]: 15 Weiss에 의해 제출되었습니다.
개요
해시 테이블은 n 요소의 집합 S(\를 m m 의 연관 A(\ A에 저장하는 데 사용되는 집합 데이터 유형의 구현입니다. 서 m m n은 시간이 더 복잡합니다.자체 밸런싱 바이너리 검색 [6]: 1 트리와 비교하여 검색, 삭제 및 삽입 작업을 수행합니다. x x는 인덱스 A [(x A [h에 저장됩니다.서h(\ h는 해시 함수이며 h < ) < h( < [6]: 2 입니다.
부하율
는 해시 테이블의 중요한 통계량이며 [1]다음과 같이 정의됩니다.
- n은 해시 테이블에서 사용되는 엔트리의 수입니다.
- k는 버킷의 수입니다.
해시테이블의 성능은 [6]: 2 에 비해 저하되므로 가 [8]1에 가까워지면 해시테이블의 크기가 조정되거나 재탕됩니다.부하계수가 max / _}/[8] 으로 떨어졌을 경우에도 테이블 크기가 변경됩니다. α(\ \alpha})의 허용 가능한 수치에는 0.6과 0.[9][10]: 110 75가 포함됩니다.
해시함수
h(\ h는 h {,. . , - h {\ h: ... 내의 또는 슬롯을 각 h , ., - 1 { {0 , 에 배열합니다. x {x \ S} m <\ m < } 。해시 함수의 기존 구현은 테이블의 모든 요소가 {,. , - { U = \ { 0 , . , u - 1} { }의 길이가 컴퓨터 [6]: 2 아키텍처의 워드 크기 내에서 제한된다는 정수 우주 가정에 기초하고 있습니다.
완벽한 h h는 SS})의 각 x({x})가 0 -({[11][12]의 고유한 값에 매핑되도록 주입함수로 정의되며,[11] 모든 키를 미리 알고 있으면 완벽한 해시함수를 생성할 수 있습니다.
정수 우주 가정
정수 우주 가정에 사용되는 해싱 방식에는 나눗셈에 의한 해싱, 곱셈에 의한 해싱, 범용 해싱, 동적 완전 해싱 및 정적 완전 [6]: 2 해싱이 포함됩니다.그러나 일반적으로 사용되는 방식은 [13]: 264 [10]: 110 나눗셈별 해싱입니다.
분할별 해시
나눗셈별 해시 방식은 다음과 같습니다.[6]: 2
곱셈에 의한 해시
곱셈에 의한 해시 방식은 다음과 같습니다.[6]: 2–3
충돌 해결
해시를 사용하는 검색 알고리즘은 두 부분으로 구성됩니다.첫 번째 부분은 검색 키를 배열 인덱스로 변환하는 해시 함수를 계산하는 것입니다.두 개의 검색 키 해시가 동일한 배열 인덱스에 없는 것이 이상적입니다.그러나 항상 그렇지는 않으며 보이지 않는 데이터에 대해 [14]: 515 보증하는 것은 불가능합니다.따라서 알고리즘의 두 번째 부분은 충돌 해결입니다.충돌 해결을 위한 두 가지 일반적인 방법은 개별 체인과 개방형 주소 [5]: 458 지정입니다.
개별 체인


별도의 체인으로 프로세스에는 각 검색 배열 인덱스에 대한 키-값 쌍이 포함된 링크 목록이 구축됩니다.충돌한 항목은 단일 링크된 목록을 통해 함께 연결되며, 이 목록을 통해 고유한 검색 [5]: 464 키로 항목에 액세스할 수 있습니다.링크 목록과의 체인을 통한 충돌 해결은 해시 테이블의 일반적인 구현 방법입니다.T T와 x x를 각각 해시 테이블과 노드로 다음과 [13]: 258 같이 동작합니다.
체인드 해시 삽입(T, k) 링크드리스트 T [h(k)]체인드 해시 검색(T, k) 링크드리스트 T [h(k)]체인드 해시 삭제(T, k)에서 키 k를 가진 요소를 검색합니다.
요소가 숫자 또는 어휘로 비교 가능하며 전체 순서를 유지하여 목록에 삽입된 경우 실패한 [14]: 520–521 검색이 더 빨리 종료됩니다.
개별 체인을 위한 기타 데이터 구조
키를 주문하면 자기 밸런싱 바이너리 검색 트리를 사용하는 등의 "자기 조직화" 개념을 사용하는 것이 효율적일 수 있습니다.이것에 의해 이론적으로 최악의 경우는 On O로 낮아질 수 있습니다.단,[14]: 521 복잡성이 더해지지만,
다이내믹 퍼펙트 해싱에서는 최악의 경우 룩업의 복잡성을 O로 줄이기 위해 2레벨 해시 테이블이 사용됩니다.이 기술에서는 kk 엔트리의 은 2 k 슬롯을 완벽한 해시 테이블로 구성되어 있으며,[15] 최악의 경우 검색 시간과 삽입에 대한 상각 시간이 단축됩니다.연구에 따르면 어레이 기반의 개별 체인은 부하가 [16]: 99 높은 표준 링크드 리스트 방식과 비교하여 97% 더 높은 성능을 발휘하는 것으로 나타났습니다.
또한 각 버킷에 대해 퓨전 트리를 사용하는 등의 기술을 사용하면 [17]가능성이 높은 모든 작업에 일정한 시간이 걸립니다.
캐싱 및 참조 위치
링크 리스트의 노드가 메모리 전체에 분산되어 있는 경우, 링크 리스트의 개별 체인 실장의 링크 리스트는 공간적인 인접성(참조 장소)에 의해 캐시에 영향을 주지 않을 수 있습니다.따라서 삽입 및 검색 중에 리스트 트래버스가 발생할 수 있습니다.[16]: 91
캐시를 의식한 변형에서는 링크 리스트 또는 셀프밸런싱 바이너리 검색 트리가 다른 체인을 통해 콜리젼을 해결하기 위해 일반적으로 캐시에 적합한 다이내믹 어레이를 사용합니다.이는 어레이의 연속적인 할당 패턴이 변환 등의 하드웨어 캐시 프리페터에 의해 악용될 수 있기 때문입니다. lookaside buffer: 접근시간과 메모리 [18][19][20]소비를 줄입니다.
오픈 어드레싱


오픈 어드레싱은 모든 엔트리 레코드가 버킷 배열 자체에 저장되고 검색을 통해 해시 해결이 실행되는 또 다른 충돌 해결 기법입니다.새 엔트리를 삽입해야 할 경우 버킷이 검사됩니다.해시된 슬롯부터 시작하여 사용 중인 슬롯이 발견될 때까지 프로브 시퀀스로 진행됩니다.항목을 검색할 때 버킷은 대상 레코드가 발견되거나 사용되지 않은 배열 슬롯이 발견될 때까지 동일한 순서로 검색됩니다. 이 슬롯은 [21]검색에 실패했음을 나타냅니다.
잘 알려진 프로브 시퀀스는 다음과 같습니다.
- 선형 프로브 - 프로브 간 간격이 고정됩니다(일반적으로 1).[22]
- 2차 프로빙 - 원래 해시 [23]: 272 계산에 의해 주어진 값에 2차 다항식의 연속적인 출력을 더함으로써 프로브 사이의 간격을 증가시킵니다.
- 이중 해시: 프로브 간의 간격이 보조 해시 [23]: 272–273 함수에 의해 계산됩니다.
로드 계수α(\가 [8][16]: 93 1에 가까워지면 프로브 시퀀스가 증가하므로 오픈 어드레싱의 성능은 개별 체인에 비해 느릴 수 있습니다.테이블이 [5]: 471 완전히 채워진 경우 로드 계수가 1에 도달하면 프로빙에 의해 무한 루프가 발생합니다.선형 프로브의 평균 비용은 클러스터 형성이 검색 시간을 [5]: 472 증가시키기 때문에 클러스터링을 피하기 위해 테이블 전체에 요소를 균일하게 분산시키는 해시 함수의 능력에 따라 달라집니다.
캐싱 및 참조 위치
슬롯은 연속된 위치에 있으므로 선형 검색을 통해 참조의 인접성으로 인해 CPU 캐시의 활용률이 향상되어 메모리 [22]지연 시간이 단축될 수 있습니다.
오픈 어드레싱을 기반으로 한 기타 충돌 해결 방법
통합 해시
병합된 해시는 별도의 체인과 오픈어드레싱의 하이브리드로 버킷 또는 노드가 [24]: 6–8 테이블 내에서 링크됩니다.이 알고리즘은 고정 메모리 [24]: 4 할당에 매우 적합합니다.병합된 해시의 충돌은 해시 테이블에서 가장 큰 인덱스 빈 슬롯을 식별하여 해결되며 충돌 값이 해당 슬롯에 삽입됩니다.버킷은 충돌하는 해시 [24]: 8 주소를 포함하는 삽입된 노드의 슬롯에도 연결됩니다.
뻐꾸기 해싱
Cuckoo 해싱은 오픈 충돌 해결 기술의 한 형태로, O(1O(1) 최악의 경우 룩업이 복잡해지고 삽입 시 상각 시간이 하게 유지됩니다.충돌은 각각 자체 해시 기능을 가진 2개의 해시 테이블을 유지함으로써 해결되며 충돌한 슬롯은 지정된 항목으로 대체되고 슬롯의 프리 점유된 요소는 다른 해시 테이블로 대체됩니다.이 프로세스는 모든 키가 테이블의 빈 버킷에 자체 스팟을 가질 때까지 계속됩니다.순서가 무한 루프 상태가 되면(임계값 루프 카운터를 유지함으로써 식별됨), 양쪽 해시 테이블이 새로운 해시 함수로 재플래시되고 절차가 계속됩니다.[25]: 124–125
홉스코치 해시
Hopscotch 해싱은 뻐꾸기 해싱, 선형 프로빙 및 체인의 요소를 버킷의 인근 개념으로 결합하는 오픈 어드레싱 기반 알고리즘입니다.버킷은 특정 점유된 버킷 주위에 후속 버킷으로 "가상"[26]: 351–352 버킷이라고도 합니다.이 알고리즘은 해시 테이블의 부하 계수가 90%를 초과할 때 더 나은 성능을 제공하도록 설계되었으며 동시 설정에서 높은 throughput을 제공하므로 크기가 조정 가능한 동시 해시 [26]: 350 테이블을 구현하는 데 적합합니다.