Statistical significance
Statistical significance is the probability that an effect is not due to just chance alone.[1][2] It is an integral part of statistical hypothesis testing where it is used as an important value judgment. In statistics, a result is considered significant not because it is important or meaningful, but because it has been predicted as unlikely to have occurred by chance alone.[3]
The present-day concept of statistical significance originated from Ronald Fisher when he developed statistical hypothesis testing in the early 20th century.[4][5][6] These tests are used to determine which outcomes of a study would lead to a rejection of the null hypothesis based on a pre-specified low probability threshold called p-values, which can help an investigator to decide if a result contains sufficient information to cast doubt on the null hypothesis.[7]
P-values are often coupled to a significance or alpha (α) level, which is also set ahead of time, usually at 0.05 (5%).[7] Thus, if a p-value was found to be less than 0.05, then the result would be considered statistically significant and the null hypothesis would be rejected. However, other significance levels, such as 0.1 or 0.01, are also used, depending on the field of study.
History
The present-day concept of statistical significance originated by Ronald Fisher when he developed statistical hypothesis testing, which he described as "tests of significance," in his 1925 publication, Statistical Methods for Research Workers.[4][5][6] Fisher suggested a probability of one-in-twenty (0.05) as a convenient cutoff level to reject the null hypothesis.[8] In their 1933 paper, Jerzy Neyman and Egon Pearson recommended that the significance level (e.g., 0.05), which they called α, be set ahead of time, prior to any data collection.[8][9]
Despite his suggestion of 0.05 as a significance level, Fisher did not intend this cutoff value to be fixed and in his 1956 publication, Statistical methods and scientific inference, he even recommended that significant levels be set according to specific circumstances.[8]
Role in statistical hypothesis testing
Statistical significance plays a pivotal role in statistical hypothesis testing where it is used to determine if a null hypothesis can be rejected or retained. A null hypothesis is the general or default statement that nothing happened or changed.[10] For a null hypothesis to be rejected as false, the result has to be identified as being statistically significant, i.e., unlikely to have occurred by chance alone.
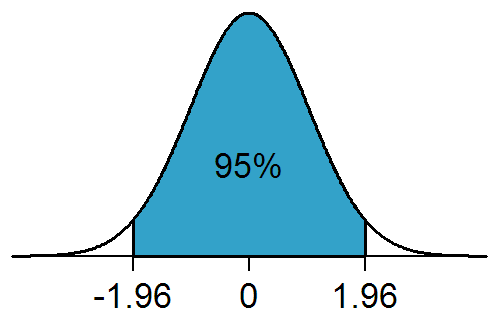
To determine if a result is statistically significant, a researcher would have to calculate a p-value, which is the probability of observing an effect given that the null hypothesis is true.[11] The null hypothesis is rejected if the p-value is less than the significance or α level. The α level is the probability of rejecting the null hypothesis when it is true (type I error) and is usually set at 0.05 (5%), which is the most widely used.[2] If the α level is 0.05, then the probability of committing a type I error is 5%.[12] Thus, a statistically significant result is one in which the p-value for obtaining that result is less than 5%, which is formally written as p < 0.05[12]
If the α level is set at 0.05, it means that the rejection region comprises 5% of the sampling distribution.[13] This 5% can be allocated to one side of the sampling distribution as in a one-tailed test or partitioned to both sides of the distribution as in a two-tailed test, with each tail (or rejection region) comprising 2.5%. One-tailed tests are more powerful than two-tailed tests, as a null hypothesis can be rejected with a less extreme result.
It is often incorrectly believed that increasing the significance level makes for a more stringent test of the null hypothesis. The thought process typically follows this pattern: Because a null hypothesis is rejected when the p-value is less than the predetermined significance level, increasing the significance level will make it more difficult for the null hypothesis to pass the hypothesis test. Because we should be skeptical of the null hypothesis, we should prefer strict tests to loose tests. This is fallacious because calculating a p-value necessarily assumes that the null hypothesis is true. As a result, rejecting a null hypothesis with a p-value of (as one example) 0.15, would be to reject a null hypothesis when there was a probability of 0.15 that evidence would have been even more extreme than the observed value.
Defining significance in terms of sigma (σ)
In specific fields such as particle physics and manufacturing, statistical significance is often expressed in units of standard deviation or sigma (σ) of a normal distribution, with significance thresholds set at a much stricter level (e.g., 5 sigma).[14][15] For instance, the certainty of the Higgs boson particle's existence was based on the 5-sigma criterion, which corresponds to a p-value of about 1 in 3.5 million.[15][16]
Criticisms
Researchers focusing solely on whether their results are statistically significant might report findings that are not necessarily substantive.[17] To gauge the research significance of their result, researchers are also encouraged to report the effect-size along with p-values, as the former describes the strength of an effect such as the distance between two means and the correlation between two variables.[18] p-values violate the likelihood principle.[19]
See also
- A/B testing
- ABX test
- Fisher's method for combining independent tests of significance
- Look-elsewhere effect
- Reasonable doubt
- Statistical hypothesis testing
References
- ^ Coolidge, Frederick L. (2012). Statistics: A Gentle Introduction (3rd ed.). Thousand Oaks, CA: SAGE Publications, Inc. pp. 1–38. ISBN 1-412-99171-4.
- ^ a b Norman, Geoffrey R.; Streiner, David L. (2008). Biostatistics: The Bare Essentials (3rd ed.). Lewiston, NY: pmph usa. pp. 46–69. ISBN 1-550-09347-9.
- ^ Sirkin, R. Mark (2005). Statistics for the Social Sciences (3rd ed.). Thousand Oaks, CA: SAGE Publications, Inc. pp. 271–316. ISBN 1-412-90546-X.
- ^ a b Poletiek, Fenna H. (2001). "Formal theories of testing". Hypothesis-testing Behaviour. Essays in Cognitive Psychology (1st ed.). East Sussex, United Kingdom: Psychology Press. pp. 29–48. ISBN 1-841-69159-3.
- ^ a b Cumming, Geoff (2011). "From null hypothesis significance to testing effect sizes". Understanding The New Statistics: Effect Sizes, Confidence Intervals, and Meta-Analysis. Multivariate Applications Series. East Sussex, United Kingdom: Routledge. pp. 21–52. ISBN 0-415-87968-X.
- ^ a b Fisher, Ronald A. (1925). Statistical Methods for Research Workers. Edinburgh, UK: Oliver and Boyd. p. 43. ISBN 0-050-02170-2.
- ^ a b Schlotzhauer, Sandra (2007). Elementary Statistics Using JMP (SAS Press) (PAP/CDR ed.). Cary, NC: SAS Institute. pp. 166–169. ISBN 1-599-94375-1.
- ^ a b c Quinn, Geoffrey R.; Keough, Michael J. (2002). Experimental Design and Data Analysis for Biologists (1st ed.). Cambridge, UK: Cambridge University Press. pp. 46–69. ISBN 0-521-00976-6.
- ^ Neyman, J.; Pearson, E.S. (1933). "The testing of statistical hypotheses in relation to probabilities a priori". Mathematical Proceedings of the Cambridge Philosophical Society. 29: 492–510. doi:10.1017/S030500410001152X.
- ^ Meier, Kenneth J.; Brudney, Jeffrey L.; Bohte, John (2011). Applied Statistics for Public and Nonprofit Administration (3rd ed.). Boston, MA: Cengage Learning. pp. 189–209. ISBN 1-111-34280-6.
- ^ Devore, Jay L. (2011). Probability and Statistics for Engineering and the Sciences (8th ed.). Boston, MA: Cengage Learning. pp. 300–344. ISBN 0-538-73352-7.
- ^ a b Healy, Joseph F. (2009). The Essentials of Statistics: A Tool for Social Research (2nd ed.). Belmont, CA: Cengage Learning. pp. 177–205. ISBN 0-495-60143-8. Cite error: The named reference "Healy" was defined multiple times with different content (see the help page).
- ^ Health, David (1995). An Introduction To Experimental Design And Statistics For Biology (1st ed.). Boston, MA: CRC press. pp. 123–154. ISBN 1-857-28132-2.
- ^ Vaughan, Simon (2013). Scientific Inference: Learning from Data (1st ed.). Cambridge, UK: Cambridge University Press. pp. 146–152. ISBN 1-107-02482-X.
- ^ a b Bracken, Michael B. (2013). Risk, Chance, and Causation: Investigating the Origins and Treatment of Disease (1st ed.). New Haven, CT: Yale University Press. pp. 260–276. ISBN 0-300-18884-6.
- ^ Franklin, Allan (2013). "Prologue: The rise of the sigmas". Shifting Standards: Experiments in Particle Physics in the Twentieth Century (1st ed.). Pittsburgh, PA: University of Pittsburgh Press. pp. Ii–Iii. ISBN 0-822-94430-8.
- ^ Carver, Ronald P. (1978). "The Case Against Statistical Significance Testing". Harvard Educational Review. 48: 378–399.
- ^ Pedhazur, Elazar J.; Schmelkin, Liora P. (1991). Measurement, Design, and Analysis: An Integrated Approach (Student ed.). New York, NY: Psychology Press. pp. 180–210. ISBN 0-805-81063-3.
- ^ Birnbaum, Allan (1962). "On the foundations of statistical inference". Journal of the American Statistical Association. 298: 269–306.
Further reading
- Ziliak, Stephen, and McCloskey, Deirdre, (2008). The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives. Ann Arbor, University of Michigan Press, 2009.
- Thompson, Bruce, (2004). The "significance" crisis in psychology and education. Journal of Socio-Economics, 33, pp. 607–613.
- Chow, Siu L., (1996). Statistical Significance: Rationale, Validity and Utility, Volume 1 of series Introducing Statistical Methods, Sage Publications Ltd, ISBN 978-0-7619-5205-3 – argues that statistical significance is useful in certain circumstances.
- Kline, Rex, (2004). Beyond Significance Testing: Reforming Data Analysis Methods in Behavioral Research Washington, DC: American Psychological Association.
External links
- The article "Earliest Known Uses of Some of the Words of Mathematics (S)" contains an entry on Significance that provides some historical information.
- "The Concept of Statistical Significance Testing" (February 1994): article by Bruce Thompon hosted by the ERIC Clearinghouse on Assessment and Evaluation, Washington, D.C.
- "What does it mean for a result to be "statistically significant"?" (no date): an article from the Statistical Assessment Service at George Mason University, Washington, D.C.