Vision AI
Extract insights from images, documents, and videos
Access advanced vision models via APIs to automate vision tasks, streamline analysis, and unlock actionable insights. Or build custom apps with no-code model training and low cost in a managed environment.
New customers get up to $300 in free credits to try Vision AI and other Google Cloud products.
You can also try deploying Google-recommended document summarizing and AI/ML image processing solutions.
Overview
What is computer vision?
Computer vision is a field of artificial intelligence (AI) that enables computers and systems to interpret and analyze visual data and derive meaningful information from digital images, videos, and other visual inputs. Some of its typical real-world applications include: object detection, visual content (images, documents, videos) processing, understanding and analysis, product search, image classification and search, and content moderation.
Advanced multimodal gen AI
Google Cloud's Vertex AI offers access to Gemini, a family of cutting-edge, multimodal model that is capable of understanding virtually any input, combining different types of information, and generating almost any output. While Gemini is best suited for tasks that mix visuals, text, and code, Gemini Pro Vision excels at a wide variety of vision related tasks, such as object recognition, digital content understanding, and captioning/description. It can be accessed through an API.
Vision focused gen AI
Imagen on Vertex AI brings Google's state-of-the-art image generative AI capabilities to application developers via an API. Some of its key features include image generation (restricted GA) with text prompts, image editing (restricted GA) with text prompts, describing an image in text (also known as visual captioning, GA), and subject model fine-tuning (restricted GA). Learn more about its key features and launch stages.
Ready-to-use Vision AI
Powered by Google’s pretrained computer vision ML models, Cloud Vision API is a readily available API (REST and RPC) that allows developers to easily integrate common vision detection features within applications, including image labeling, face and landmark detection, optical character recognition (OCR), and tagging of explicit content.
Each feature you apply to an image is a billable unit—Cloud Vision API lets you use 1,000 units of its features for free every month. See pricing details.
Document understanding gen AI
Document AI is a document understanding platform that combines computer vision and other technologies such as natural language processing to extract text and data from scanned documents, transforming unstructured data into structured information and business insights.
It offers a wide range of pretrained processors optimized for different types of documents. It also makes it easy to build custom processors to classify, split, and extract structured data from documents via Document AI Workbench.

Ready-to-use Vision AI for videos
With computer vision technology at its core, Video Intelligence API is an easy way to process, analyze, and understand video content.
Its pretrained ML models automatically recognize a vast number of objects, places, and actions in stored and streaming video, with exceptional quality. It’s highly efficient for common use cases such as content moderation and recommendation, media archives, and contextual advertisements. You can also train custom ML models with Vertex AI Vision for your specific needs.

Visual Inspection AI
Visual Inspection AI automates visual inspection tasks in manufacturing and other industrial settings. It leverages advanced computer vision and deep learning techniques to analyze images and videos, identify anomalies, detect and locate defects, and check missing and defect parts in assembled products.
You can train custom models with no technical expertise and minimum labeled images, efficiently run inference at production lines, and continuously refresh models with fresh data from the factory floor.

Unified Vision AI Platform
Vertex AI Vision is a fully managed application development environment that lets developers easily build, deploy, and manage computer vision applications to process a variety of data modalities, such as text, image, video, and tabular data. It reduces time to build from days to minutes at one tenth the cost of current offerings.
You can build and deploy your own custom models, and manage and scale them with CI/CD pipelines. It also integrates with popular open source tools like TensorFlow and PyTorch.

Data privacy and security
Google Cloud has industry-leading capabilities that give you—our customers—control over your data and provide visibility into when and how your data is accessed.
As a Google Cloud customer, you own your customer data. We implement stringent security measures to safeguard your customer data and provide you with tools and features to control it on your terms. Customer data is your data, not Google’s. We only process your data according to your agreement(s).
Learn more in our Privacy Resource Center.
Compare computer vision products
| Offering | Best for | Key features |
|---|---|---|
Quick and easy integration of basic vision features. | Prebuilt features like image labeling, face and landmark detection, OCR, safe search. Cost-effective, pay-per-use. | |
Extracting insights from scanned documents and images, automating document workflows. | OCR (powered by Gen AI), NLP, ML for document understanding, text extraction, entity identification, document categorization. | |
Analyzing video content, content moderation and recommendation, media archives, and contextual ads. | Object detection and tracking, scene understanding, activity recognition, face detection and analysis, text detection and recognition. | |
Automating visual inspection tasks in manufacturing and industrial settings | Detecting anomaly, detecting and locating defects, and checking assembly. | |
Building and deploying custom models for specific needs. | Data preparation tools, model training and deployment, complete control over your solution. Requires technical expertise. | |
Visual analysis and understanding, multimodal question answering. | Info seeking, object recognition, digital content understanding, structured content generation, captioning/description, and extrapolation. | |
Get automated image descriptions. Image classification and search. Content moderation and recommendations. | Image generation, image editing, visual captioning, and multimodal embedding. See full list of features and their launch stages. |
Optimized for different purposes, these products allow you to take advantage of pretrained ML models and hit the ground running, with the ability to easily fine-tune.
Quick and easy integration of basic vision features.
Prebuilt features like image labeling, face and landmark detection, OCR, safe search.
Cost-effective, pay-per-use.
Extracting insights from scanned documents and images, automating document workflows.
OCR (powered by Gen AI), NLP, ML for document understanding, text extraction, entity identification, document categorization.
Analyzing video content, content moderation and recommendation, media archives, and contextual ads.
Object detection and tracking, scene understanding, activity recognition, face detection and analysis, text detection and recognition.
Automating visual inspection tasks in manufacturing and industrial settings
Detecting anomaly, detecting and locating defects, and checking assembly.
Building and deploying custom models for specific needs.
Data preparation tools, model training and deployment, complete control over your solution. Requires technical expertise.
Visual analysis and understanding, multimodal question answering.
Info seeking, object recognition, digital content understanding, structured content generation, captioning/description, and extrapolation.
Get automated image descriptions.
Image classification and search.
Content moderation and recommendations.
Image generation, image editing, visual captioning, and multimodal embedding.
See full list of features and their launch stages.
Optimized for different purposes, these products allow you to take advantage of pretrained ML models and hit the ground running, with the ability to easily fine-tune.
How It Works
Google Cloud’s Vision AI suite of tools combines computer vision with other technologies to understand and analyze video and easily integrate vision detection features within applications, including image labeling, face and landmark detection, optical character recognition (OCR), and tagging of explicit content.
These tools are available via APIs while remaining customizable for specific needs.
Google Cloud’s Vision AI suite of tools combines computer vision with other technologies to understand and analyze video and easily integrate vision detection features within applications, including image labeling, face and landmark detection, optical character recognition (OCR), and tagging of explicit content.
These tools are available via APIs while remaining customizable for specific needs.

Demo
See how computer vision works with your own files
Common Uses
Detect text in raw files and automatically summarize
Summarize large documents with gen AI
The solution depicted in the architecture diagram on the right deploys a pipeline that is triggered when you add a new PDF document to your Cloud Storage bucket. The pipeline extracts text from your document, creates a summary from the extracted text, and stores the summary in a database for you to view and search.
You can invoke the application by either uploading files via Jupyter Notebook, or directly to Cloud Storage in the Google Cloud console.
Estimated deployment time: 11 mins (1 min to configure, 10 min to deploy).
How-tos
Summarize large documents with gen AI
The solution depicted in the architecture diagram on the right deploys a pipeline that is triggered when you add a new PDF document to your Cloud Storage bucket. The pipeline extracts text from your document, creates a summary from the extracted text, and stores the summary in a database for you to view and search.
You can invoke the application by either uploading files via Jupyter Notebook, or directly to Cloud Storage in the Google Cloud console.
Estimated deployment time: 11 mins (1 min to configure, 10 min to deploy).
Build an image processing pipeline
Scalable image processing on a serverless architecture
The solution, depicted in the diagram on the right, uses pretrained machine learning models to analyze images provided by users and generate image annotations. Deploying this solution creates an image processing service that can help you handle unsafe or harmful user-generated content, digitize text from physical documents, detect and classify objects in images, and more.
You will be able to review configuration and security settings to understand how to adapt the image processing service to different needs.
Estimated deployment time: 12 mins (2 mins to configure, 10 mins to deploy).
How-tos
Scalable image processing on a serverless architecture
The solution, depicted in the diagram on the right, uses pretrained machine learning models to analyze images provided by users and generate image annotations. Deploying this solution creates an image processing service that can help you handle unsafe or harmful user-generated content, digitize text from physical documents, detect and classify objects in images, and more.
You will be able to review configuration and security settings to understand how to adapt the image processing service to different needs.
Estimated deployment time: 12 mins (2 mins to configure, 10 mins to deploy).
Get automated image descriptions with gen AI
The Visual Captioning feature of Imagen lets you generate a relevant description for an image, You can use it to get more detailed metadata about images for storing and searching, to generate automated captioning to support accessibility use cases, and receive quick descriptions of products and visual assets.
Available in English, French, German, Italian, and Spanish, this feature can be accessed in the Google Cloud console, or via an API call.
How-tos
The Visual Captioning feature of Imagen lets you generate a relevant description for an image, You can use it to get more detailed metadata about images for storing and searching, to generate automated captioning to support accessibility use cases, and receive quick descriptions of products and visual assets.
Available in English, French, German, Italian, and Spanish, this feature can be accessed in the Google Cloud console, or via an API call.
Stream-process videos
Gain insights from streaming videos with Vertex AI Vision
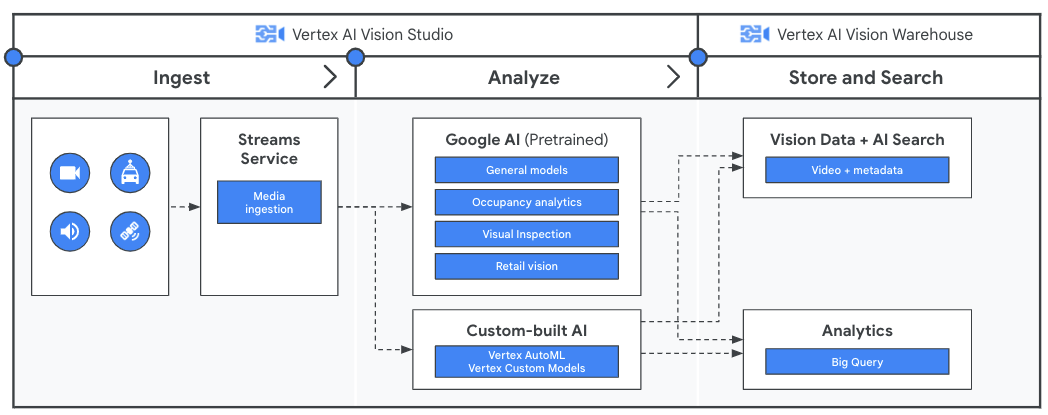
Before analyzing your video data with your application, create a pipeline for the continuous flow of data with Streams service in Vertex AI Vision. Ingested data is then analyzed by Google’s pretrained models or your custom model. The analysis output from the streams is then stored in Vertex AI Vision Warehouse where you can use advanced AI-powered search capabilities to query unstructured media content.
How-tos
Gain insights from streaming videos with Vertex AI Vision
Before analyzing your video data with your application, create a pipeline for the continuous flow of data with Streams service in Vertex AI Vision. Ingested data is then analyzed by Google’s pretrained models or your custom model. The analysis output from the streams is then stored in Vertex AI Vision Warehouse where you can use advanced AI-powered search capabilities to query unstructured media content.
Extract text and insights from documents with generative AI
Unlock insights from nuanced documents with Document AI
Powered by a foundational model, Document AI Custom Extractor extracts text and data from generic and domain-specific documents faster and with higher accuracy. Easily fine-tune with just 5-10 documents for even better performance.
If you want to train your own model, auto-label your datasets with the foundational model for faster time to production.
You can also choose to use pretrained specialized processors—see the full list of processors.
How-tos
Unlock insights from nuanced documents with Document AI
Powered by a foundational model, Document AI Custom Extractor extracts text and data from generic and domain-specific documents faster and with higher accuracy. Easily fine-tune with just 5-10 documents for even better performance.
If you want to train your own model, auto-label your datasets with the foundational model for faster time to production.
You can also choose to use pretrained specialized processors—see the full list of processors.
High-precision visual inspection
Automate quality inspection with Visual Inspection AI
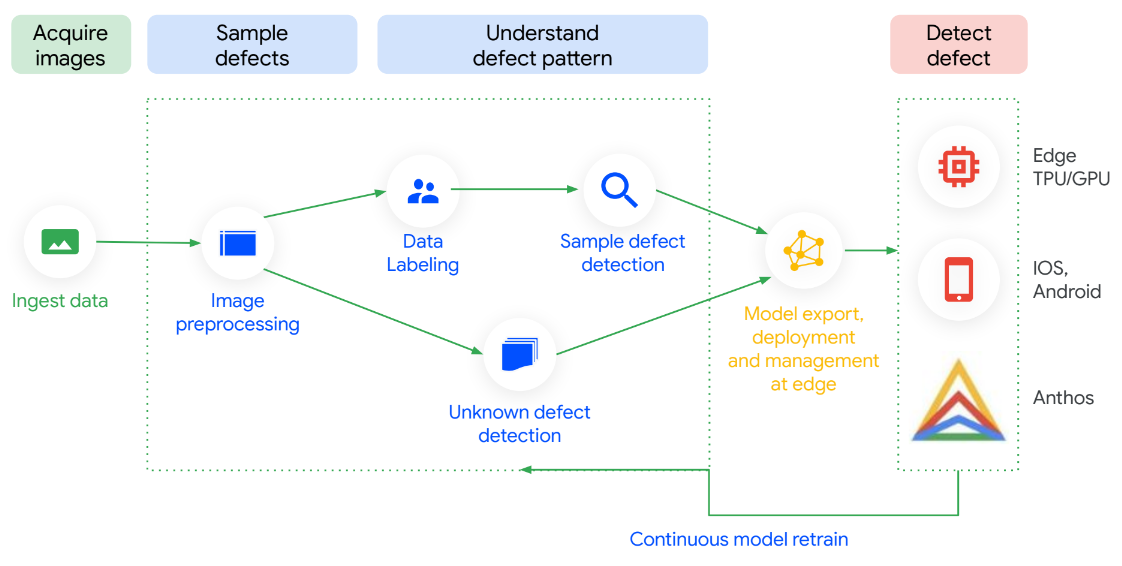
Visual Inspection AI is optimized in every step so it’s easy to set up and fast to see ROI. With up to 300 times fewer labeled images to start training high-performance inspection models than general purpose ML platforms, it has shown to deliver up to 10 times higher accuracy. You can train models with no technical expertise, and they run on-premises. Best of all, the models can be continuously refreshed with data flowing from the factory floor, giving you increased accuracy as you discover new use cases.
How-tos
Automate quality inspection with Visual Inspection AI
Visual Inspection AI is optimized in every step so it’s easy to set up and fast to see ROI. With up to 300 times fewer labeled images to start training high-performance inspection models than general purpose ML platforms, it has shown to deliver up to 10 times higher accuracy. You can train models with no technical expertise, and they run on-premises. Best of all, the models can be continuously refreshed with data flowing from the factory floor, giving you increased accuracy as you discover new use cases.
Pricing
| How Vision AI pricing works | Each vision offering has a set of features or processors, which have different pricing—check the detailed pricing pages for details. | ||
|---|---|---|---|
| Free tier | Product/Service | Discounted pricing | Details |
Vision API | First 1,000 units every month are free | 5,000,001+ units per month | |
Document AI | N/A Pricing is processor-sensitive. | 5,000,001+ pages per month for Enterprise Document OCR Processor | |
Video Intelligence API | First 1,000 minutes per month are free | 100,000+ minutes per month | |
Vertex AI Vision | N/A Pricing is feature-sensitive. |
| |
Imagen—multimodal embeddings |
|
| US $0.0001 per image input |
Imagen—visual captioning |
|
| US $0.0015 per image |
Gemini Pro Vision | |||
How Vision AI pricing works
Each vision offering has a set of features or processors, which have different pricing—check the detailed pricing pages for details.
Vision API
First 1,000 units
every month are free
5,000,001+ units
per month
Document AI
N/A
Pricing is processor-sensitive.
5,000,001+ pages
per month for Enterprise Document OCR Processor
Video Intelligence API
First 1,000 minutes
per month are free
100,000+ minutes
per month
Vertex AI Vision
N/A
Pricing is feature-sensitive.
Imagen—multimodal embeddings
US $0.0001
per image input
Imagen—visual captioning
US $0.0015
per image