Explore open source blog posts >
The post How GitHub protects developers from copyright enforcement overreach appeared first on The GitHub Blog.
]]>Some platforms handle copyright takedowns with a “three strikes and you’re out” policy, automatically blocking user accounts after repeated notices. While that might sound fair, it can lead to unjust outcomes, especially for open source developers who routinely fork popular projects that could become subject to a copyright takedown. If your account gets suspended, that can have immediate negative consequences not just for you, but for all the open source projects you maintain. Code is collaborative, complex, and often reused, which makes enforcement challenging, and amplifies the downstream effects of takedowns. At GitHub, we take a developer-first approach, reviewing each case individually before blocking accounts, and making sure copyright enforcement doesn’t derail legitimate work.
The U.S. Supreme Court is about to decide a case that could change how platforms like GitHub handle copyright claims — and by extension, it could also impact how you build and share code. In Cox Communications v. Sony Music Entertainment, the question is: When can an internet service provider or platform be held liable for copyright infringement committed by its users? Google, Microsoft (with GitHub), Amazon, Mozilla, and Pinterest have urged the Court to adopt a clear rule: Liability should only apply when there’s “conscious, culpable conduct that substantially assists the infringement,” not merely awareness or inaction.
This matters to developers because the platforms you depend on to host, share, and deploy code rely on legal protections called safe harbors to avoid constant liability for user-generated content. One of the most important safe harbors is Section 512 of the Digital Millennium Copyright Act (DMCA), which shields services from copyright infringement liability as long as they follow a formal notice-and-takedown process. For GitHub, this protection is especially critical given the collaborative nature of open source, the functional role of code, and the ripple effects of removing code that may be widely used.
With over 150 million developers and 518 million projects on GitHub, we process hundreds of DMCA takedowns each month, but also receive thousands of automated, incomplete, or inaccurate notices. If “awareness” alone were enough for liability, platforms could be forced to over-remove content based on flawed notices — chilling innovation and collaboration across the software ecosystem. GitHub’s DMCA Takedown Policy supports copyright protection while limiting disruption for legitimate projects, offering a clear path for appeal and reinstatement, and providing transparency by publishing valid DMCA takedown notices to a public DMCA repository.
This case matters to GitHub as a platform and to all developers who use internet service providers to create and collaborate. We’re in good company: the Supreme Court docket for the case includes amicus briefs from a wide range of civil society stakeholders including Engine Advocacy, the Electronic Frontier Foundation, and Public Knowledge advocating on behalf of free expression, the open internet, and how common-sense limitations on liability make it possible for the modern internet to function. We will continue to monitor the case as it moves forward and remain committed to advocating on behalf of software developers everywhere.
Updates to our Transparency Center
An important aspect of our commitment to developers is our approach to developer-first content moderation. We try to restrict content in the narrowest way possible to address violations, give users the chance to appeal, and provide transparency around our actions.
We’ve updated the GitHub Transparency Center with the first half of 2025 data, which includes a repo of structured data files. In this latest update, we wanted to clarify how we report and visualize government takedowns.
Here’s what we changed:
- We have combined the category of government takedowns received based on local law and based on Terms of Service into one chart/reporting category of Government takedowns received. We made this change to be more accurate in our reporting; the government takedown requests we receive may cite a local law or a Terms of Service violation, but more typically, they are just official requests for the removal of content.
- We have retained the separate categories of “Government takedowns processed based on local law” and “Government takedowns processed based on Terms of Service.” This is an important distinction because it reflects that some content governments ask us to take down is in violation of our Terms and is processed like any other report, whereas some content is not in violation of our terms, but is in violation of local law. In the latter case, we limit the impact on developers by only restricting access to the content in the jurisdiction in which we are legally required to do so, and we publish the request in our gov-takedowns repository to ensure transparency.
- We have also clarified the README of our gov-takedowns repository to note that the repository solely contains official government requests, which led to content removal based on local law.
These are small clarifications, but it’s important to be clear and accurate with the data we share so that researchers studying platform moderation and government suppression of information can use our data. If that applies to you, and you have feedback on our reporting, research to share, or reporting categories you would find useful, open an issue in our transparency center repo.
Updates to our Acceptable Use Policies
We have opened a pull request and 30-day notice-and-comment period for a proposed update to our Acceptable Use Policies (AUP), which would reorganize several existing AUP provisions into separate policies with additional guidance. The new policies include:
- Child Sexual Abuse Material (CSAM)
- Terrorist & Violent Extremist Content (TVEC)
- Non-Consensual Intimate Imagery
- Synthetic Media and AI Tools
The Synthetic Media and AI Tools policy will be extended to explicitly disallow CSAM and TVEC in accordance with international laws. Read more about our approach to deepfake tools.
We invite all stakeholders to review and comment on the proposed Acceptable Use Policy additions for the 30-day period until October 16.
The post How GitHub protects developers from copyright enforcement overreach appeared first on The GitHub Blog.
]]>The post Q1 2025 Innovation Graph update: Bar chart races, data visualization on the rise, and key research appeared first on The GitHub Blog.
]]>We launched the GitHub Innovation Graph to give developers, researchers, and policymakers an easy way to explore and analyze global trends in open source software development. It offers a reliable, transparent dataset that tracks public collaboration activity across regions over time.
Our latest quarterly update now includes data through March 2025, which means the Innovation Graph spans more than five years of insights into the global software economy.
Data visualization and AI continue to gain momentum, and more broadly, the Innovation Graph is becoming an increasingly valuable resource for anyone looking to ground their work in trusted, real-world developer data.
Let’s jump in.
Bar chart race videos now available on global metrics pages
We’ve added bar chart race videos to the git pushes, repositories, developers, and organizations global metrics pages.
data-visualization enters the topics leader board
In Q1 2025, data-visualization finally appeared as one of the top 50 topics by the number of unique pushers:

Starting from way down in rank 100 in Q1 2020, it’s been an arduous journey:
Not every repository topic has the kind of trajectory as ai:
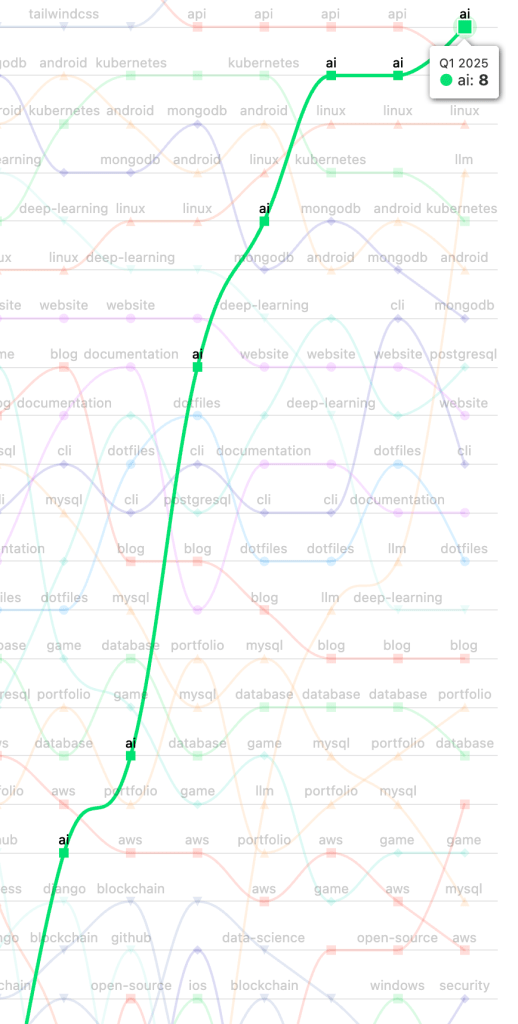
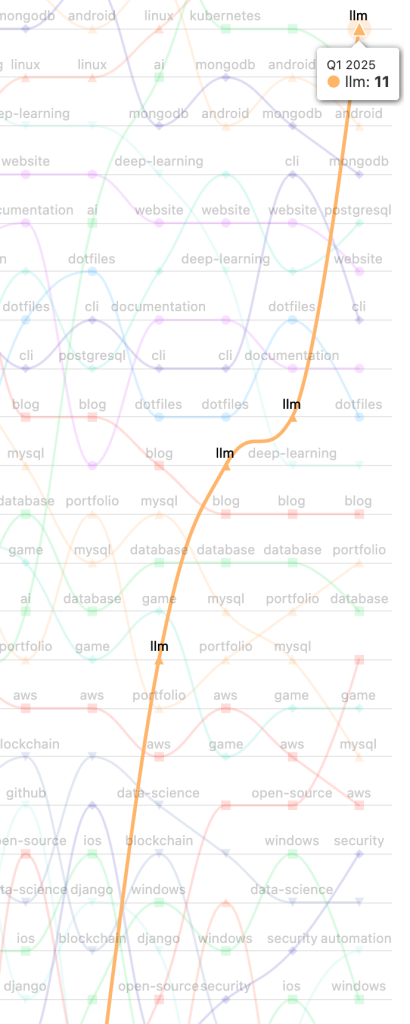
Or llm:
Research roundup
Finally, we’d like to highlight some of the recent research reports and papers that caught our interest — and that utilize GitHub and Innovation Graph data:
The 2025 AI Index Report
Published by the Stanford Institute for Human-Centered AI (HAI), the AI Index Report tracks and monitors trends in AI development and diffusion, synthesizing insights relevant to businesses, policymakers, researchers, and the general public. Check out Section 1.6 of the report for their analysis of public AI-related software projects on GitHub over time, showing a sharp increase in 2024.
- Nestor Maslej, Loredana Fattorini, Raymond Perrault, Yolanda Gil, Vanessa Parli, Njenga Kariuki, Emily Capstick, Anka Reuel, Erik Brynjolfsson, John Etchemendy, Katrina Ligett, Terah Lyons, James Manyika, Juan Carlos Niebles, Yoav Shoham, Russell Wald, Tobi Walsh, Armin Hamrah, Lapo Santarlasci, Julia Betts Lotufo, Alexandra Rome, Andrew Shi, Sukrut Oak. “The AI Index 2025 Annual Report,” AI Index Steering Committee, Institute for Human-Centered AI, Stanford University, Stanford, CA, April 2025.
Corporate Accelerators and Global Entrepreneurial Growth
Researchers found that participating in a corporate accelerator program increased startups’ future funding by more than 40%. Innovation Graph data was used as a measure of regional technical labor capacity.
- Impink, Stephen Michael and Wright, Nataliya and Seamans, Robert, Corporate Accelerators and Global Entrepreneurial Growth (June 12, 2025). Columbia Business School Research Paper No. 5291626, HEC Paris Research Paper No. SPE-2025-1572, Available at SSRN: https://ssrn.com/abstract=5291626 or http://dx.doi.org/10.2139/ssrn.5291626.
The building blocks of software work explain coding careers and language popularity
Researchers analyzed StackOverflow to develop a large-scale, fine-grained taxonomy of software development tasks. They found that in particular, Python developers are more likely to pursue tasks associated with higher wages, possibly because Python’s versatility enables them to more readily pick up skills in disparate and unfamiliar areas. Innovation Graph data provided a way to assess the representativeness of the distribution of programming languages used by StackOverflow users.
- Feng, X., Wachs, J., Daniotti, S. and Neffke, F., 2025. The building blocks of software work explain coding careers and language popularity. arXiv preprint arXiv:2504.03581.
Who is using AI to code? Global diffusion and impact of generative AI
Researchers trained a classifier to detect AI-generated Python functions, finding that AI generated 30% of Python functions committed on GitHub by US developers. This resulted in a 2.4% increase in total quarterly commit volume, which generates an estimated $9.6-14.4 billion in value annually.
- Daniotti, Simone, Johannes Wachs, Xiangnan Feng, and Frank Neffke. “Who is using AI to code? Global diffusion and impact of generative AI.” arXiv preprint arXiv:2506.08945 (2025).
Societal Capacity Assessment Framework: Measuring Advanced AI Implications for Vulnerability, Resilience, and Transformation
Researchers developed an indicators-based approach to assessing societal resilience to advanced AI across three dimensions: structural factors that might predispose a society to AI risks (“vulnerability”); capacity to prevent, absorb, and recover from AI risks (“resilience”); and capacity to leverage AI systems to mitigate AI risks and reconfigure the society toward systemic safety (“transformation”). The Innovation Graph was cited in the prototype framework as a data source to use as a proxy to measure a society’s human capital in the domain of cyber security.
- Milan M. Gandhi, Peter Cihon, Owen C. Larter, and Rebecca Anselmetti. 2025. Societal Capacity Assessment Framework: Measuring Advanced AI Implications for Vulnerability, Resilience, and Transformation. In ICML Workshop on Technical AI Governance (TAIG). Retrieved from https://openreview.net/forum?id=8gn9NeL0Ai.
The post Q1 2025 Innovation Graph update: Bar chart races, data visualization on the rise, and key research appeared first on The GitHub Blog.
]]>The post We need a European Sovereign Tech Fund appeared first on The GitHub Blog.
]]>Open source software is open digital infrastructure that our economies and societies rely on. Nevertheless, open source maintenance continues to be underfunded, especially when compared to physical infrastructure like roads or bridges. So we ask: how can the public sector better support open source maintenance?
As part of our efforts to support developers, GitHub’s developer policy team has commissioned a study from Open Forum Europe, Fraunhofer ISI and the European University Institute that explores how one of the open source world’s most successful government programs, the German Sovereign Tech Agency, can be scaled up to the European Union level. That study was published today. Here’s what it says and what you can do to help make the EU Sovereign Tech Fund (EU-STF) a reality.
The maintenance challenge
There is a profound mismatch between the importance of open source maintenance and the public attention it receives. The demand-side value of open source software to the global economy is estimated at $8.8 trillion, and the European Commission’s own research shows that OSS contributes a minimum of €65-95 billion to the EU economy annually. Basic open source technologies, such as libraries, programming languages, or software development tools, are used in all sectors of the economy, society, and public administrations.
| Open source is everywhere | Open source is valuable | Open source is underfinanced |
|---|---|---|
| 96% of all code bases contain OSS | $8.8T demand-side value to global economy | 1/3 of OSS maintainers are unpaid |
| 77% of a given code base is OSS | €65-95M minimum contribution to annual EU GDP | 1/3 are the only maintainer of their OSS project |
The flip side of everybody benefiting from this open digital infrastructure is that too few feel responsible for paying the tab. The Sovereign Tech Agency’s survey of over 500 OSS maintainers showed that a third of them are not paid at all for their maintenance work, but would like to be. Another third earns some income from OSS maintenance, but is not able to make a living off this work. Perhaps even more alarmingly, a third of respondents are solo maintainers, and almost three quarters of surveyed projects are maintained by three people or fewer. As prominent security incidents such as the xz backdoor or the Log4Shell vulnerability have shown in recent years, it can mean serious risks for the OSS community’s health and the security of our global software ecosystem if too much is put on the shoulders of small, overworked, and underappreciated teams.
At GitHub, we are helping address this open source sustainability challenge through GitHub Sponsors, the GitHub Secure Open Source Fund, free security tooling for maintainers, and other initiatives. Yet we recognize that there is a significant gap between the immense public value of open source software and the funding that is available to maintain it, a gap that this research is seeking to address.
Designing an impactful fund
Building on the success story of the German Sovereign Tech Agency, which has invested over €23 million in 60 OSS projects in its first two years of operation (2022-2024), the EU-STF should have five main areas of activity:
- Identifying the EU’s most critical open source dependencies,
- Investments in maintenance,
- Investments in security,
- Investments in improvement,
- Strengthening the open source ecosystem.
The study proposes two alternative institutional setups for the EU-STF: either the creation of a centralized EU institution (the moonshot model), or a consortium of EU member states that provide the initial funding and apply for additional resources from the EU budget (the pragmatic model). In both cases, to make the fund a success, the minimum contribution from the upcoming EU multiannual budget should be no less than €350 million. This would not be enough to meet the open source maintenance need, but it could form the basis for leveraging industry and national government co-financing that would make a lasting impact.
Equipped with the learnings from the German Sovereign Tech Agency and other government open source programs, such as the US Open Technology Fund or the EU’s Next Generation Internet initiative, the study identified seven design criteria that the EU-STF must meet:
- Pooled financing. To address the maintenance funding gap, industry, national governments and the EU should all be able to put money into the same pot. It is not in the interest of overworked open source maintainers to have to research and apply to dozens of separate funds, all with slightly different funding criteria. That’s why GitHub’s Secure Open Source Fund pools funding from many industry partners into one coherent program. The EU-STF should follow the same logic and be capable of collecting contributions from industry, national governments and the EU budget alike.
- Low bureaucracy. If you’re one of those aforementioned unpaid solo maintainers, the last thing you need is to sink several days of work into a complicated application process with an uncertain outcome that many EU funding programs are unfortunately known for. The EU-STF should combine a lightweight application process along with its own research to identify and proactively contact critical OSS infrastructure projects. Funding recipients should have limited reporting requirements to make sure that they can spend their time on improving the health of their OSS projects, not jumping through administrative hoops.
- Political independence. Public funding programs often follow technological trends, such as blockchain, quantum computing or AI. Open source maintenance often gets overlooked, because it is neither a new development nor limited to a particular economic sector: it is foundational to all of them. An EU-STF has to be politically independent enough to shield it from frequent pivots to new, politically salient topics, and instead keep it focused on the mission of securing and maintaining our public software infrastructure.
- Flexible funding. There is no one-size-fits-all model for open source maintenance. Many maintainers are hired by companies to work on OSS as part of their day jobs. Others maintain projects in their free time. Some critical OSS projects are governed by a foundation or other nonprofit, yet others are made up of a loose collective of individuals scattered across the globe. The EU-STF should be able to fund individuals, nonprofits or companies in all of those cases for their OSS maintenance work. Living in the EU should not be a requirement for receiving funding, just like the German Sovereign Tech Agency does not restrict funding to Germans. To benefit the EU economy and society, software doesn’t have to be Made in the EU, as long as it is Made Open Source.
- Community focus. A fund that is solely run by career public servants is going to struggle to develop the expertise and build the trust with the open source ecosystem that are necessary to make a positive impact on open source sustainability. The EU-STF should collaborate with the open source community to co-define funding priorities and design the funding process.
- Strategic alignment. To be attractive enough to the European Union to justify spending a budget of a minimum of €350 million on open source sustainability, the EU-STF has to demonstrate a positive impact on the EU’s strategic goals. The study lays out in detail how open source maintenance funding contributes to economic competitiveness, digital sovereignty (that is, the ability of individuals, companies and the state to use and design technology according to their own needs), and cybersecurity, for example by helping companies comply with their supply chain security obligations for open source components under the Cyber Resilience Act.
- Transparency. As with any case of spending taxpayer money, the EU-STF must meet the highest standards of transparency in governance and funding decisions, to ensure that it can earn the trust not just of the open source community, but also of the policymakers who approve its budget.
Making the EU Sovereign Tech Fund a reality
Right now, the European Union is ramping up the negotiations on its new multi-year budget for the period of 2028-2035, the Multiannual Financial Framework. GitHub’s developer policy team is presenting the findings of the study to EU legislators and mobilizing the support of industry partners to demonstrate the need for a novel instrument that allows the public and private sectors to work together on securing our open source infrastructure. We are delighted to partner with Mercedes-Benz, who contributed a foreword to the study and have been vocal supporters of the idea of an EU Sovereign Tech Fund from its inception.
Without sustainable funding and support, it is entirely foreseeable that ever more open source software projects will not receive the diligence and scrutiny appropriate for software of such criticality.
Magnus Östberg, Chief Software Officer, Mercedes-Benz AG; Markus Rettstatt, Vice President Software Defined Car, Tech Innovation GmbH
The first legislative proposals for the EU budget have just hit the desks of the European Parliament and the national governments in the Council of Ministers. Whether you are an individual, a member of an open source organization, or a company representative, you can voice your support for the creation of the EU-STF to the European Commission, your elected representatives in the European Parliament, and your national government. If you’re at EU Open Source Summit Europe on August 26, you can join us for a presentation of the study and community discussion.
The post We need a European Sovereign Tech Fund appeared first on The GitHub Blog.
]]>The post Racing into 2025 with new GitHub Innovation Graph data appeared first on The GitHub Blog.
]]>We launched the GitHub Innovation Graph to give developers, researchers, and policymakers an easy way to analyze trends in public software collaboration activity around the world. With today’s quarterly1 release, updated through December 2024, we now have five full years of data.
To help us celebrate, we’ve created some animated bar charts showcasing the growth in developers and pushes of some of the top economies around the world over time. Enjoy!
Animated bar charts
What a photo finish! The European Union surpassing the United States in cumulative git pushes was certainly a highlight, but we’d also note the significant movements of Brazil and Korea in climbing up the rankings.
Another close race, this time showing India outpacing the European Union in repositories between Q2 and Q3 2024.
Zooming into economies in APAC, we can appreciate the speed of developer growth in India, more than quadrupling in just 5 years.
Flying over to EMEA, we saw very impressive growth from Nigeria, which rose up from rank 20 in Q1 2020 to rank 11 in Q4 2024.
Finally, in LATAM, it was exciting to see how close most of the economies are in developer counts (with the exception of Brazil), with frequent back-and-forth swaps in rankings between economies like Argentina and Colombia, or Guatemala and Bolivia.
Want to explore more? Dive into the datasets yourself. We can’t wait to check out what you build.
Global line charts
We’ve also made a feature update that will enable you to quickly understand the global scale of some of the metrics we publish, including the numbers of public git pushes, repositories, developers, and organizations on GitHub worldwide.
Simply follow the installation steps for our newly released GitHub MCP Server, and you’ll be able to prompt GitHub Copilot in agent mode within VS Code to retrieve the CSVs from the data repo using the get_file_contents tool. Then, you can have the agent sum up the latest values for you.
Afterward, you can double-check its results with these handy charts that we’ve added to their respective global metrics pages for git pushes, repositories, developers, and organizations. Check them out below.
- The GitHub Innovation Graph reports metrics according to calendar year quarters, which correspond to the following: Q1: January 1 to March 31; Q2: April 1 to June 30; July 1 to September 30; and Q4: October 1 to December 31. ↩
The post Racing into 2025 with new GitHub Innovation Graph data appeared first on The GitHub Blog.
]]>The post Engaging with the developer community on our approach to content moderation appeared first on The GitHub Blog.
]]>Our developer-first approach to content moderation is adapted to the unique environment of code collaboration and has evolved to meet specific needs through a suite of content moderation tools. We’ve discussed the nuances and challenges of moderating a code collaboration platform in the Journal of Online Trust and Safety in an effort to be transparent about our own practices and contribute to the research base of platform studies.
We want to bring this discussion directly to the developers that make GitHub what it is. Recently, we attended FOSDEM, Europe’s largest free and open source developer conference. We connected with developers and presented a deep dive into how our approach to platform moderation has been informed by the values of the FOSS community. You can watch the video of the talk here. We’ll also be presenting this talk on March 8 at SCaLE 22x, the 22nd Annual Southern California Linux Expo in Pasadena, CA. We don’t want to just share our own work—we want to hear directly from developers and maintainers about the challenges you’re facing.
Developers are an important stakeholder in how we moderate our platform, and we want to hear from you. Check out our site-policy repo to contribute constructive ideas, questions, and feedback to make our policies better. We also welcome participation in our developer-policy repo where you can share public policy opportunities and challenges to advance developers’ rights to innovation, collaboration, and equal opportunity.
The post Engaging with the developer community on our approach to content moderation appeared first on The GitHub Blog.
]]>The post That’s a wrap: GitHub Innovation Graph in 2024 appeared first on The GitHub Blog.
]]>This is our first GitHub Innovation Graph data release in 2025 and our first data release after celebrating the Innovation Graph’s first birthday, so we’d like to reflect a bit on how things have gone so far and share our hopes and dreams for the future.
Innovation Graph: a look back
We created the Innovation Graph to help make GitHub data more easily available to researchers, policymakers, and developers. Unfortunately, no one’s made a Dataset Success Graph yet to make dataset success metrics more easily available, so in lieu of that, here’s a chart of the github/innovationgraph repo’s stars, annotated with open source-related events to help explain the increases over time:

The Innovation Graph might not get VC funding anytime soon with these rookie numbers, but we’re heartened to see the steady growth over the past year and a quarter, and we’re hopeful that this imperfect proxy is at least somewhat correlated with usefulness. Let’s dive into each event category below.
Innovation Graph data releases
We’ve released five quarters’ worth of additional data since the launch of the Innovation Graph (mostly like clockwork–thanks for your patience with this latest release, it’s been a busy couple of quarters!). With each release, we’ve seen modest increases in star count. Taken together with the results of a recently published working paper on the association between semantic versioning and adoption of software packages, we have to wonder if we’re leaving stars on the table by only bumping the patch version with each dataset release, as new major releases are apparently associated with significantly greater growth in adoption than patch (or minor) releases.
Academic papers
Speaking of papers, here’s a roundup of some that caught our attention because they lined up with research questions about the open source ecosystem that were on our wishlist, or because they grappled with the impact of AI on software production, or both.
The Value of Open Source Software
The demand-side value of open source software was estimated to be $8.8 trillion.
- Hoffmann, Manuel and Nagle, Frank and Zhou, Yanuo, “The Value of Open Source Software” (January 1, 2024). Harvard Business School Strategy Unit Working Paper No. 24-038, Available at SSRN: https://ssrn.com/abstract=4693148 or http://dx.doi.org/10.2139/ssrn.4693148
Generative AI and the Nature of Work
Access to GitHub Copilot was found to cause open source maintainers to do proportionally more coding work and less project management work, as well as explore more lucrative programming languages. Check out our researcher Q&A with a couple of the co-authors for more details.
- Hoffmann, Manuel and Boysel, Sam and Nagle, Frank and Peng, Sida and Xu, Kevin, “Generative AI and the Nature of Work” (October 27, 2024). Harvard Business School Strategy Unit Working Paper No. 25-021, Harvard Business Working Paper No. No. 25-021, CESifo Working Paper Series No. 11479, Available at SSRN: https://ssrn.com/abstract=5007084 or http://dx.doi.org/10.2139/ssrn.5007084
Measuring Software Innovation with Open Source Software Development Data
Major releases of OSS packages were found to count as a unit of innovation complementary to scientific publications, patents, and standards, offering applications for policymakers, managers, and researchers.
- Brown, Eva Maxfield, et al. “Measuring Software Innovation with Open Source Software Development Data.” arXiv preprint arXiv:2411.05087 (2024).
Open Source Software Policy in Industry Equilibrium
Global and domestic impacts of China and US government restrictions on, disincentives against, and subsidies for open source software contribution were estimated using simulations. Restrictions were found to be ineffective at increasing domestic investment into OSS; disincentives were found to increase costs both domestically and globally; and subsidies were found to both increase domestic investment and decrease costs globally.
- Gortmaker, Jeff. “Open Source Software Policy in Industry Equilibrium.” Working Paper (2024).
Impact of the Availability of ChatGPT on Software Development: A Synthetic Difference in Differences Estimation using GitHub Data
Availability of ChatGPT was found to cause an increase in Git pushes per 100,000 inhabitants and increases in developer engagement across high-level languages like Python and JavaScript, while the effects on domain-specific languages like HTML and SQL varied. Learn more through our researcher Q&A with a couple of the co-authors.
- Quispe, Alexander, and Rodrigo Grijalba. “Impact of the Availability of ChatGPT on Software Development: A Synthetic Difference in Differences Estimation using GitHub Data.” arXiv preprint arXiv:2406.11046 (2024).
From GitHub to GDP: A framework for measuring open source software innovation
A methodology was developed to generate estimates of investment in OSS that are consistent with the U.S. national accounting methods used for measuring software investment. U.S. investment in OSS in 2019 was estimated to be $37.8 billion with a current-cost net stock of $74.3 billion.
- Gizem Korkmaz, J. Bayoán Santiago Calderón, Brandon L. Kramer, Ledia Guci, Carol A. Robbins, “From GitHub to GDP: A framework for measuring open source software innovation,” Research Policy, Volume 53, Issue 3, 2024, 104954, ISSN 0048-7333, https://doi.org/10.1016/j.respol.2024.104954.
Conferences
There were too many conferences to list, but we know that the Innovation Graph and other datasets on GitHub activity made a splash in presentations at the following conferences (in part because many of the above papers were presented at these conferences):
- OpenForum Academy (OFA) Symposium 2023 and 2024
- National Bureau of Economic Research (NBER) Summer Institute 2024
- AI at Wharton 2nd Annual Business & Generative AI Workshop
- Tilburg University Conference of the Workplace of the Future
- State of Open Con 24
News publications
There were also too many news articles to list, but we were happy to see The Economist and Rest of World using Innovation Graph data and we’ll consider adding year-over-year percentage growth charts to the Innovation Graph site to save data journalists some time.
Reports
We’re glad to have had the continued opportunity to contribute to the 2023 and 2024 editions of the WIPO Global Innovation Index and similarly, to the 2023 and 2024 Stanford AI Index Reports. And of course, we’re thrilled with the excitement and energy that the annual State of the Octoverse report generates around GitHub data each year, with its narrative structure that helps contextualize a wide array of topics.
This year, to complement macro-level reports that use large-scale aggregate data like those above, we also supported two surveys to shed light on the composition, motivations, and perspectives of the open source community and its funders: the 2024 edition of the Open Source Survey and the inaugural Open Source Software Funding Survey.
Our hopes and dreams for the future
In a word: more. 2024 was our first full year of the Innovation Graph and it’s been nothing short of delightful to meet new collaborators, reconnect with existing ones, and continue building an evidence base to demonstrate the impact of open source. As we kick off 2025, we look forward to even more collaboration to come!
The post That’s a wrap: GitHub Innovation Graph in 2024 appeared first on The GitHub Blog.
]]>The post Inside the research: How GitHub Copilot impacts the nature of work for open source maintainers appeared first on The GitHub Blog.
]]>I’m excited to share an interview with two researchers that I’ve had the privilege of collaborating with on a recently released paper studying how open source maintainers adjust their work after they start using GitHub Copilot:
- Manuel Hoffmann is a postdoctoral scholar at the Laboratory for Innovation Science at Harvard housed within the Digital, Data, and Design Institute at Harvard Business School. He is also affiliated with Stanford University. His research interests lie in social and behavioral aspects around open source software and artificial intelligence, under the broader theme of innovation and technology management, with the aim of better understanding strategic aspects for large, medium-sized, and entrepreneurial firms.
- Sam Boysel is a postdoctoral fellow at the Laboratory for Innovation Science at Harvard. He is an applied microeconomist with research interests at the intersection of digital economics, labor and productivity, industrial organization, and socio-technical networks. Specifically, his work has centered around the private provision of public goods, productivity in open collaboration, and welfare effects within the context of open source software (OSS) ecosystems.
Research Q&A
Kevin: Thanks so much for chatting, Manuel and Sam! So, it seems like the paper’s really making the rounds. Could you give a quick high-level summary for our readers here?
Manuel: Thanks to the great collaboration with you, Sida Peng from Microsoft and Frank Nagle from Harvard Business School, we study the impact of GitHub Copilot on developers and how this generative AI alters the nature of work. We find that when you provide developers in the context of open source software with a generative AI tool that reduces the cost of the core work of coding, developers increase their coding activities and reduce their project management activities. We find our results are strongest in the first year after the introduction but still exist even two years later. The results are driven by developers who are working more autonomously and less collaboratively since they do not have to engage with other humans to solve a problem but they can solve the problem through AI assistance.


Sam: That’s exactly right. We tried to even further understand the nature of work by digging into the paradigm of exploration vs exploitation. Loosely speaking, exploitation is the idea to exert effort towards the most lucrative of the already known options while exploration implies to experiment to find new options with a higher potential return. We tested this idea in the context of GitHub. Developers that had access to GitHub Copilot are engaged in more experimentation and less exploitation, that is, they start new projects with access to AI and have a lower propensity to work on older projects. Additionally, they expose themselves to more languages that they were previously not exposed to and in particular to languages that are valued higher in the labor market. A back-of-the-envelope calculation from purely experimentation among new languages due to GitHub Copilot suggests a value of around half a billion USD within a year.
Kevin: Interesting! Could you provide an overview of the methods you used in your analysis?
Manuel: Would be happy to! We are using a regression discontinuity design in this work, which is as close as you can get to a randomized control trial when purely using pre-existing data, such as the one from GitHub, without introducing randomization by the researcher. Instead, the regression discontinuity design is based on a ranking of developers and a threshold that GitHub uses to determine eligibility for free access to GitHub Copilot’s top maintainer program.
Sam: The main idea of this method is that a developer that is right below the threshold is roughly identical to a developer that is right above the threshold. Stated differently, by chance a developer happened to have a ranking that made them eligible for the generative AI while they could as well not have been eligible. Taken together with the idea that developers neither know the threshold nor the internal ranking from GitHub, we can be certain that the changes that we observe in coding, project management, and the other activities on the platform are only driven by the developers having access to GitHub Copilot and nothing else.
Kevin: Nice! Follow-up question: could you provide an “explain like I’m 5” overview of the methods you used in your analysis?
Manuel: Sure thing, let’s illustrate the problem a bit more. Some people use GitHub Copilot and others don’t. If we just looked at the differences between people who use GitHub Copilot vs. those who don’t, we’d be able to see that certain behaviors and characteristics are associated with GitHub Copilot usage. For example, we might find that people who use GitHub Copilot push more code than those who don’t. Crucially, though, that would be a statement about correlation and not about causation. Often, we want to figure out whether X causes Y, and not just that X is correlated with Y. Going back to the example, if it’s the case that those who use GitHub Copilot push more code than those who don’t, these are a few of the different explanations that might be at play:
- Using GitHub Copilot causes people to push more code.
- Pushing more code causes people to use GitHub Copilot.
- There’s something else that both causes people to use GitHub Copilot and causes them to push more code (for example, being a professional developer).
Because (1), (2), and (3) could each result in data showing a correlation between GitHub Copilot usage and code pushes, just finding a correlation isn’t super interesting. One way you could isolate the cause and effect relationship between GitHub Copilot and code pushes, though, is through a randomized controlled trial (RCT).
In an RCT, we randomly assign people to use GitHub Copilot (the treatment group), while others are forbidden from using GitHub Copilot (the control group). As long as the assignment process is truly random and the users comply with their assignments, any outcome differences between the treatment and control groups can be attributed to GitHub Copilot usage. In other words, you could say that GitHub Copilot caused those effects. However, as anyone in the healthcare field can tell you, large-scale RCTs over long-time periods are often prohibitively expensive, as you’d need to recruit subjects to participate, monitor them to see if they complied with their assignments, and follow up with them over time.
Sam: That’s right. So, instead, wouldn’t it be great if there would be a way to observe developers without running an RCT and still draw valid causal conclusions about GitHub Copilot usage? That’s where the regression discontinuity design (RDD) comes in. The random assignment aspect of an RCT allows us to compare the outcomes of two virtually identical groups. Sometimes, however, randomness already exists in a system, which we can use as a natural experiment. In the case of our paper, this randomness came in the form of GitHub’s internal ranking for determining which open source maintainers were eligible for free access to GitHub Copilot.
Let’s walk through a simplified example. Let’s imagine that there were one million repositories that were ranked on some set of metrics and the rule was that the top 500,000 repositories are eligible for free access to GitHub Copilot. If we compared the #1 ranked repository with the #1,000,000 ranked repository, then we would probably find that those two are quite different from each other. After all, the #1 repository is the best repository on GitHub by this metric while the #1,000,000 repository is a whole 999,999 rankings away from it. There are probably meaningful differences in code quality, documentation quality, project purpose, maintainer quality, etc. between the two repositories, so we would not be able to say that the only reason why there was a difference in outcomes for the maintainers of repository #1 vs. repository #1,000,000 was because of free access to GitHub Copilot.
However, what about repository #499,999 vs. repository #500,001? Those repositories are probably very similar to each other, and it was all down to random chance as to which repository made it over the eligibility threshold and which one did not. As a result, there is a strong argument that any differences in outcomes between those two repositories is solely due to repository #499,999 having free access to GitHub Copilot and repo #500,001 not having free access. Practically, you’ll want to have a larger sample size than just two, so you would compare a narrow set of repositories just above and below the eligibility threshold against each other.
Kevin: Thanks, that’s super helpful. I’d be curious about the limitations of your paper and data that you wished you had for further work. What would the ideal dataset(s) look like for you?
Manuel: Fantastic question! Certainly, no study is perfect and there will be limitations. We are excited to better understand generative AI and how it affects work in the future. As such, one limitation is the availability of information from private repositories. We believe that if we were to have information on private repositories we could test whether there is some more experimentation going on in private projects and that project improvements that were done with generative AI in private may spill over to the public to some degree over time.
Sam: Another limitation of our study is the language-based exercise to provide a value of GitHub Copilot. We show that developers focus on higher value languages that they did not know previously and we extrapolated this estimate to all top developers. However, this estimate is certainly only a partial equilibrium value since developer wages may change over time in a full equilibrium situation if more individuals offer their services for a given language. However, despite the limitation, the value seems to be an underestimate since it does not contain any non-language specific experimentation value and non-experimentation value that is derived from GitHub Copilot.
Kevin: Predictions for the future? Recommendations for policymakers? Recommendations for developers?
Manuel: One simple prediction for the future is that AI incentivizes the activity for which it lowers the cost. However, it is not clear yet which parts will be incentivized through AI tools since they can be applied to many domains. It is likely that there are going to be a multitude of AI tools that incentivize different work activities which will eventually lead to employees, managers at firms, and policy-makers having to consider on which activity they want to put weight. We also would have to think about new recombinations of work activities. Those are difficult to predict. Avi Goldfarb, a prolific professor from the University of Toronto, gave an example of the steam engine with his colleagues. Namely, work was organized in the past around the steam engine as a power source but once electric motors were invented, that was not necessary anymore and structural changes happened. Instead of arranging all of the machinery around a giant steam engine in the center of the factory floor, electricity enabled people to design better arrangements, which led to boosts in productivity. I find this historical narrative quite compelling and can imagine similarly for AI that the greatest power still remains to be unlocked and that it will be unlocked once we know how work processes can be re-organized. Developers can think as well about how their work may change in the future. Importantly, developers can actively shape that future since they are closest to the development of machine learning algorithms and artificial intelligence technologies.
Sam: Adding on to those points, it is not clear when work processes change and whether it will have an inequality reducing or enhancing effect. Many predictions point towards an inequality enhancing effect since the training of large-language models requires substantial computing power which is often only in the hands of a few players. On the other hand, it has been documented that especially lower ability individuals seem to benefit the most from generative AI, at least in the short-term. As such, it’s imperative to understand how the benefits of generative AI are distributed across society. If not, are there equitable, welfare-improving interventions that can correct these imbalances? An encouraging result of our study suggests that generative AI can be especially impactful for relatively lesser skilled workers:
 for more information with summary statistics of each proxy.](https://github.blog/wp-content/uploads/2024/12/coding_by_ability.png?w=1024&resize=2300%2C1126)
 for more information with summary statistics of each proxy.](https://github.blog/wp-content/uploads/2024/12/project_management_by_ability.png?w=1024&resize=2316%2C1082)
Sam (continued): Counter to widespread speculation that generative AI will replace many entry level tasks, we find reason to believe that AI can also lower the costs of experimentation and exploration, reduce barriers to entry, and level the playing field in certain segments of the labor market. It would be prudent for policymakers to monitor distributional effects of generative AI, allowing the new technology to deliver equitable benefits where it does so naturally but at the same time intervening in cases where it falls short.
Personal Q&A
Kevin: I’d like to change gears a bit to chat more about your personal stories. Manuel, I know you’ve worked on research analyzing health outcomes with Stanford, diversity in TV stations, and now you’re studying nerds on the internet. Would love to learn about your journey to getting there.
Manuel: Sure! I was actually involved with “nerds on the internet” longer than my vita might suggest. Prior to my studies, I was using open source software, including Linux and Ubuntu, and programming was a hobby for me. I enjoyed the freedom that one had on the personal computer and the internet. During my studies, I discovered economics and business studies as a field of particular interest. Since I was interested in causal inference and welfare from a broader perspective, I learned how to use experimental and quasi-experimental studies to better understand social, medical and technological innovation that are relevant for individuals, businesses, and policy makers. I focused on labor and health during my PhD and afterwards I was able to lean a bit more into health at Stanford University. During my time at Harvard Business School, the pendulum swung back a bit towards labor. As such, I was in the fortunate position—thanks to the study of the exciting field of open source software—to continuously better understand both spaces.
Kevin: Haha, great to hear your interest in open source runs deep! Sam, you also have quite the varied background, analyzing cleantech market conditions and the effects of employment verification policies, and you also seem to have been studying nerds on the internet for the past several years. Could you share a bit about your path?
Sam: I’ve been a computing and open source enthusiast since I got my hands on a copy of “OpenSUSE for Dummies” in middle school. As an undergraduate, I was drawn to the social science aspect of economics and its ability to explain or predict human behavior across a wide range of settings. After bouncing around a number of subfields in graduate school, I got the crazy idea to combine my field of study with my passion and never looked back. Open source is an incredibly data-rich environment with a wealth of research questions interesting to economists. I’ve studied the role of peer effects in driving contribution, modelled the formation of software dependency networks using strategic behavior and risk aversion, and explored how labor market competition shapes open source output.
And thanks, Kevin. I’ll be sure to work “nerds on the internet” into the title of the next paper.
Kevin: Finding a niche that you’re passionate about is such a joy, and I’m curious about how you’ve found living in that niche. What’s the day-to-day like for you both?
Manuel: The day-to-day can vary but as an academic, there are a few tasks that are recurring at a big picture level. Research, teaching and other work. Let’s focus on the research bucket. I am quite busy with working on causal inference papers, refining them but also speaking to audiences to communicate our work. Some of the work is done jointly, some by oneself, so there is a lot of variation, and the great part of being an academic is that one can choose that variation oneself through the projects one selects. Over time one has to juggle many balls. Hence, I am working on finishing prior papers in the space of health; for example, some that you alluded to previously on Television, Health and Happiness and Vaccination at Work, but also in the space of open source software, importantly, to improve the paper on Generative AI and the Nature of Work. We have continuously more ideas to better understand the world we are living and going to live in at the intersection of open source software and generative AI and, as such, it is very valuable to relate to the literature and eventually answer exciting questions around the future of work with real world data. GitHub is a great resource for that.
Sam: As an applied researcher, I use data to answer questions. The questions can come from current events, from conversations with both friends and colleagues, or simply musing on the intricacies of the open source space. Oftentimes the data comes from publicly observed behavior of firms and individuals recorded on the internet. For example, I’ve used static code analysis and version control history to characterize the development of open source codebases over time. I’ve used job postings data to measure firm demand for open source skills. I’ve used the dependency graphs of packaging ecosystems to track the relationships between projects. I can then use my training in economic theory, econometric methodology, and causal inference to rigorously explore the question. The end result is written up in an article, presented to peers, and iteratively improved from feedback.
Kevin: Have things changed since generative AI tooling came along? Have you found generative AI tools to be helpful?
Manuel: Definitely. I use GitHub Copilot when developing experiments and programming in Javascript together with another good colleague, Daniel Stephenson from Virginia Commonwealth University. It is interesting to observe how often Copilot actually makes code suggestions based on context that are correct. As such, it is an incredibly helpful tool. However, the big picture of what our needs are can only be determined by us, as such, in my experience Copilot does seem to speed up the process and leads to avoiding some mistakes conditional on not just blindly following the AI.
Sam: I’ve only recently begun using GitHub Copilot, but it’s had quite an impact on my workflow. Most social sciences researchers are not skilled software engineers. However, they must also write code to hit deadlines. Before generative AI, the delay between problem and solution was usually characterized by many search queries, parsing Q&A forums or documentation, and a significant time cost. Being able to resolve uncertainty within the IDE is incredible for productivity.
Kevin: Advice you might have for folks who are starting out in software engineering or research? What tips might you give to a younger version of yourself, say, from 10 years ago?
Manuel: I will talk a bit at a higher level. Find work, questions or problems that you deeply care about. I would say that is a universal rule to be satisfied, be it in software engineering, research or in any other area. In a way, think about the motto, “You only live once,” as a pretty applicable misnomer. Another universal advice that has high relevance is to not care too much about the things you cannot change but focus on what you can control. Finally, think about getting advice from many different people, then pick and choose. People have different mindsets and ideas. As such, that can be quite helpful.
Sam:
- Being able to effectively communicate with both groups (software eng and research) is extremely important.
- You’ll do your best work on things you’re truly passionate about.
- Premature optimization truly is the root of all evil.
Kevin: Learning resources you might recommend to someone interested in learning more about this space?
Manuel: There are several aspects we have touched upon—Generative AI Research, Coding with Copilot, Causal Inference and Machine Learning, Economics, and Business Studies. As such, here is one link for each topic that I can recommend:
- Generative AI research: Ethan Mollick’s social media posts
- Coding with Copilot: Advanced GitHub Copilot features
- Causal Inference and Machine Learning: Susan Athey’s Lab
- Economics and Business Studies: NBER Working Papers
I am sure that there are many other great resources out there, many that can also be found on GitHub.
Sam: If you’re interested to get more into how economists and other social scientists think about open source, I highly recommend the following (reasonably entry-level) articles that have helped shape my research approach.
- Lerner, J., & Tirole, J. (2002). Some Simple Economics of Open Source. The Journal of Industrial economics, 50(2), 197-234.
- Bessen, J., & Maskin, E. (2009). Sequential innovation, patents, and imitation. The RAND Journal of Economics, 40(4), 611-635.
- Athey, S., & Ellison, G. (2014). Dynamics of open source movements. Journal of Economics & Management Strategy, 23(2), 294-316.
For those interested in learning more about the toolkit used by empirical social scientists:
- Cunningham, S. (2021). Causal Inference: The Mixtape. Yale University Press. (website)
(shameless plug) We’ve been putting together a collection of data sources for open source researchers. Contributions welcome!
Kevin: Thank you, Manuel and Sam! We really appreciate you taking the time to share about what you’re working on and your journeys into researching open source.
The post Inside the research: How GitHub Copilot impacts the nature of work for open source maintainers appeared first on The GitHub Blog.
]]>The post The nuances and challenges of moderating a code collaboration platform appeared first on The GitHub Blog.
]]>In the most recent period, you may notice a significant jump in projects affected by DMCA takedowns, with 1,041 notices processed and 18,472 projects taken down in H1 2024 versus 964 notices and 6,358 projects taken down in H2 2023. This jump can largely be attributed to a single takedown.
Moderating GitHub presents challenges specific to the code collaboration environment, but policymakers, researchers, and other stakeholders are often less familiar with how a platform like GitHub works. That’s one of the reasons our policy team regularly advocates on behalf of the interests of developers, code collaboration, and open source development. Open source software is a public good, underpinning all sectors of the economy and serving as essential digital infrastructure, and moderating the home for open source software requires careful consideration to ensure that essential code remains accessible. Meanwhile, our Trust and Safety team has continually evolved our developer-first approach to content moderation in response to technological and societal developments.
In the interest of broadening understanding of code collaboration, advancing the transparency of our own governance practices, and enriching platform studies research, we are proud to share the recently published article, “Nuances and Challenges of Moderating a Code Collaboration Platform” in the Journal of Online Trust and Safety and co-authored by members of our Trust and Safety, Legal, and Policy teams. The paper is available to all, and we encourage you to read it in its entirety. It covers how moderating a code collaboration platform presents unique considerations illustrated with diverse case studies. We also consider how the new frontiers of AI will present challenges and opportunities for maintaining our developer-first standards at scale.

The post The nuances and challenges of moderating a code collaboration platform appeared first on The GitHub Blog.
]]>The post 2024 is the biggest global election year in history. What’s at stake for developers? appeared first on The GitHub Blog.
]]>While tech policy impacts us all, these elections are particularly relevant to software developers because public policy influences who has the access and opportunity to participate in global code collaboration. In a significant election year for developers, GitHub is considering what is at stake for our users and platform, how we can take responsible action to support free and fair elections, and how developers contribute to resilient democratic processes.
These elections are occurring at an inflection point for AI policy. Policymakers are looking to encourage the immense societal benefits of AI while mitigating potential harms. Their decisions will have a significant impact on burgeoning technologies because they influence the opportunities, resources, and regulations that constrain and enliven innovation. For example, to understand the success of Silicon Valley, one can look at how United States law created conditions for the tech industry to flourish, by, for example, shielding intermediaries from strict liability for user-generated content, while other regulatory regimes impeded innovation. AI-powered developer tools have the potential to democratize access, so that anyone can be a developer, and accelerate productivity, with recent research estimating that generative AI-powered developer tools could boost global GDP by over $1.5 trillion. We have the opportunity to chart a path forward for AI policy that balances opportunity with risk, encouraging mindful inventorship at all levels, from hobbyists and entrepreneurs to large organizations.
It’s clear that we need policies that consider and represent the interests of developers and open source, but this is easier said than done. While open source underpins innovation and economic vitality–with an estimated 96% of codebases containing open source–it is too often misunderstood by policymakers unaware of its benefits and misinformed about its risks. GitHub worked to get the balance right in the European Union’s AI Act and Cyber Resilience Act to protect open source and avoid undue burden on developers, advocating for clear exemptions for open source to avoid chilling innovation. We need developer champions in public office who don’t just understand the value of open source and nuances of software development but are pursuing innovative ideas to support open source sustainability like the Open Technology Fund’s FOSS Sustainability Fund and Germany’s Sovereign Tech Fund.
This massive election year represents an opportunity to strengthen policymaker understanding and collaboration with the global developer community. Worldwide efforts to nationalize digital space driven by cybersecurity concerns, competition, and censorship cut people off from mutually beneficial open innovation and the ability to benefit their local communities. We need leaders who want to protect and support the ability for anyone, anywhere to become a software developer and contribute to shared knowledge and advancement in the open. A critical area of influence is the global availability of platforms like GitHub, which is home to over 100 million developers collaborating on code throughout the world. While complying with sanctions we work to keep as much of GitHub available to as many developers as feasible under U.S. sanctions laws, by securing licenses to make public repositories accessible, as much as possible, worldwide.
This significant global election year has challenged us to consider GitHub’s role within the information ecosystem and how we can govern our platform responsibly. Policymakers and journalists are concerned about the impact of deepfakes and other AI-generated disinformation on elections as observed in large democracies like India, where the fears of AI generated information warfare were not entirely realized, but deepfake trolling certainly was, and the United States, where the US Federal Communications Commission banned AI-generated voices in robocalls following troubling deepfakes. While GitHub is not a general purpose social media platform where people virally share deepfakes, or an AI-powered media generating platform, we are a platform where users may research and develop tools to generate or detect synthetic media and want to take responsible action. That’s why we joined the AI Elections Accord, a tech accord to combat the deceptive use of AI in elections. The AI Elections Accord establishes principles for signatories to manage the risks arising from deceptive AI election content. In line with this commitment, GitHub updated our Acceptable Use Policies to address the development of synthetic and manipulated media tools for the creation of non-consensual intimate imagery (NCII) and disinformation, which seeks to strike a balance between addressing misuses of synthetic media tools while enabling legitimate research on these technologies. If we ban these tools altogether, the research community has no way to evaluate the way they work and offer insights to help prevent their abuse. Through balancing safety and accessibility, platforms can encourage the benefits of open models while safeguarding from potential risks.
Developers are significant stakeholders who build the tools that guide our information ecosystem and have an important role to play in protecting elections. Look at the Coalition for Content Provenance and Authenticity (C2PA), an industry-leading effort to address the prevalence of misleading information through the development of technical standards for certifying the source and history (or provenance) of media content, built with open source components and made available in a public GitHub repository. Or consider the Content Authenticity Initiative, a cross-industry consortium that advocates for the adoption of content credentials based on C2PA standards and provides an open source software development kit (SDK) of tools and libraries that enable developers to create, verify, and display content credentials based on C2PA standards.
Protecting our information ecosystem with content provenance and authenticity initiatives is a collaborative effort underpinned by open source. VotingWorks, the only open source voting system used in United States elections, is working to strengthen public trust in elections through open source code, documentation, and development.
These are just a few examples of the important work that open source developers are doing to support democratic processes. Even the simple act of a developer sharing their work and contributing to the world’s open knowledge base contributes to shared human progress.
The post 2024 is the biggest global election year in history. What’s at stake for developers? appeared first on The GitHub Blog.
]]>The post How researchers are using GitHub Innovation Graph data to estimate the impact of ChatGPT appeared first on The GitHub Blog.
]]>We launched the GitHub Innovation Graph to make it easier for researchers, policymakers, and developers to access longitudinal metrics on software development for economies around the world. We’re pleased to report that researchers are indeed finding the Innovation Graph to be a useful resource, and with today’s Q1 2024 data release, I’m excited to share an interview with two researchers who are using data from the Innovation Graph in their work:
- Alexander Quispe is a junior researcher at the World Bank in the Digital Development Global Practice and lecturer in the Department of Economics at PUCP.
- Rodrigo Grijalba is a data scientist who specializes in Causal Inference, Economics, Artificial Intelligence-integrated systems, and their intersections.
Research Q&A
Kevin: First of all, Alexander, thanks so much for your bug report in the data repository for the Innovation Graph! Glad you took the initiative to reach out about the data gap, both so that we could fix the missing data and learn about your fascinating work on the paper that you and Rodrigo presented at the Munich Summer Institute in May. Could you give a quick high-level summary for our readers here?
Alexander: In recent years, advancements in artificial intelligence (AI) have revolutionized various fields, with software development being one of the most impacted. The rise of large language models (LLMs) and tools like OpenAI’s ChatGPT and GitHub Copilot, has brought about a significant shift in how developers approach coding, debugging, and software architecture. Our research specifically analyzes the impact of ChatGPT on the velocity of software development, finding that the availability of ChatGPT:
- Significantly increased the number of Git pushes per 100,000 inhabitants of each country.
- Had a positive (although not statistically significant) correlation with the number of repositories and developers per 100,000 inhabitants.
- Generally enhanced developer engagement across various programming languages. High-level languages like Python and JavaScript showed significant increases in unique developers, while the impact on domain-specific languages like HTML and SQL varied.
These results would imply that the impact of ChatGPT thus far does not lie in the increase of developers or projects, but in an acceleration of the pre-established development process.
Rodrigo: GitHub’s Innovation Graph data worked very well with the methods we used, especially the synthetic ones. Having country- and language-level aggregated data meant that we could neatly define our control and treatment groups, and disaggregate them again to find how effects differed, say, by language. There actually are several other disaggregations we could do with this data and we might look into that in the future, but the language differences seemed like the most obvious faceting approach to explore.
Kevin: Interesting! Could you provide an overview of the methods you used in your analysis?
Alexander: We mainly focused on comparative methods for panel data in observational studies, with the goal of estimating the average treatment effect. Our main method used synthetic difference in differences (SDID), as described by Arkhangelsky, Athey, Imbens, and Wager (2021). We also described the results for the difference in differences (DiD) and synthetic control (SC) methods.
Kevin: Nice! Follow-up question: could you provide an “explain like I’m 5” overview of the methods you used in your analysis?
Alexander: Haha sure, we looked at Innovation Graph data at multiple points in time (“panel data”) in order to try to estimate the impact of ChatGPT access for the average country (“average treatment effect”). Since this data wasn’t part of a randomized experiment (for example, if ChatGPT was available only to a randomly selected group of countries), this was an “observational study.” In situations where you’re unable to run a randomized experiment, but you still want to be able to say something like “X caused Y to increase by 10%,” you can use causal inference techniques (like DiD, SC, and SDID) to help estimate the causal effect of a treatment.
Kevin: Huh, that reminds me of the last release of our transparency reporting data, where we found that a change in our DMCA takedown form caused a 15X increase in the number of DMCA notices alleging circumvention:

Alexander: Oh yes, in causal inference terms, that’s called an “event study,” where there’s a prior trend that changes due to some event, in your case, the DMCA form update. In an event study, you’re trying to compare what actually happened vs. the counterfactual of what would have happened if the event didn’t occur by comparing the time periods from before and after the event. In your case, the dark blue line showing the number of DMCA notices processed due to circumvention seems to extend the prior trend, so it happens to also plot the counterfactual, that is, what would have happened if the form wasn’t updated:

Alexander (continued): Sometimes, though, instead of comparing the time periods before/after a treatment, you might want to make a comparison between a group that received a treatment vs. a group that was never treated. For example, maybe you’re interested in estimating the causal effect of bank bailouts during the Great Depression, so you’d like to compare what happened to banks that could access funds from the federal government vs. those that couldn’t. DiD, SC, and SDID are techniques that you can use to try to compare treated vs. untreated groups to figure out what would have happened in the counterfactual scenario if a treatment didn’t happen, and thus, estimate the effect of the treatment. In our paper, that treatment is the legal availability of ChatGPT in certain countries but not others.

Notes: The gray solid line and the dashed black line represent the average number of pushes per 100k inhabitants by quarter for the treated and (synthetic) control groups, respectively. The dashed red vertical line indicates the start of the treatment. The light blue areas at the bottom indicate the importance of pre-treatment quarters for predicting post-treatment levels in the control group. Visually, both groups are nearly parallel before the launch of ChatGPT, but start noticeably diverging after the launch. We can interpret the average treatment effect as the magnitude of this divergence.

Notes: here we present the estimated treatment effect by language: the squares represent the estimates, and the lines represent their 95% confidence intervals. All the results shown here are statistically significant, although some are very small. The estimated treatment effects are larger for JavaScript, Python, TypeScript, Shell, HTML, and CSS, and smaller for Rust, C, C++, Assembly, Batchfile, PowerShell, R, MATLAB, and PLpgSQL.
A full explanation of DiD, SC, and SDID probably wouldn’t fit in this Q&A (although see additional learning resources at the bottom), but walking through our analysis briefly: I preferred the SDID method for our analysis because the parallel trends assumption required for the DiD method did not hold for our treatment and control groups. Additionally, the SC method could not be precise due to our limited data for pre-treatment periods, only eleven quarters. The SDID method addresses these limitations by constructing a synthetic control group while also considering pre-treatment period differences, making it a robust choice for our analysis.
Kevin: I’d be curious about the limitations of your paper and data that you wished you had for further work. What would the ideal dataset(s) look like for you?
Alexander:
Limitations
During my presentation at the Summer Institute in Munich, some researchers critiqued our methodology by highlighting that even if countries faced restrictions on ChatGPT, individuals might have used VPNs to bypass these restrictions. This potential workaround could undermine the validity of using these countries as a control group. However, I referred to studies by Kreitmeir and Raschky (2023) and del Rio-Chanona et al. (2023), which acknowledged that while VPNs allow access to ChatGPT, these barriers still pose significant hurdles to widespread and rapid adoption. Therefore, the restrictions remain a valid consideration in our analysis.
Data for future work
I would like to conduct a similar analysis using administrative data at the software developer level. Specifically, I aim to compare the increase in productivity for those who have access to GitHub Copilot with those who do not. Additionally, if we could obtain user experience metrics, we could explore heterogeneous results among users leveraging Copilot. This data would enable us to deepen our understanding of the impact of AI-assisted development tools on individual productivity and software development practices.
Kevin: Predictions for the future? Recommendations for policymakers? Recommendations for developers?
Alexander: The future likely holds increased integration of AI tools like ChatGPT and GitHub Copilot in software development processes. Given the significant positive impact observed on the number of Git pushes, repositories, and unique developers, we can predict that AI-driven development tools will become standard in software engineering.
Policymakers should consider the positive impacts of AI tools like ChatGPT and GitHub Copilot on productivity and support their integration into various sectors. Deregulating access to such tools could foster economic growth by enhancing developer efficiency and accelerating software production.
Developers should embrace AI tools like ChatGPT and GitHub Copilot to boost their productivity and efficiency. By leveraging these tools for coding, debugging, and optimizing software, developers can focus on more complex and creative aspects of software engineering.
Personal Q&A
Kevin: I’d like to change gears a bit to chat more about your personal stories. Alexander, it seems like you’ve got a deep economics background but you also use your computer science skills to write and maintain software libraries for causal inference techniques. Working with fellow economists to build software seems like a pretty unique role. Would love to learn about your journey to getting there.
Alexander: Yes, I love the intersection between economics and computer science. This journey began while I was working as a research associate at MIT. I was taking a causal ML course taught by Victor Chernozhukov, and he was looking for someone to translate tutorials from R to Python. This was in early 2020 before large language models existed. From there, I started collaborating with Victor on creating tutorials and developing Python and Julia software for causal ML methods. I realized that most advanced econometric techniques were primarily written in Stata or R, which limited their use in industry. It felt like a niche area at the time. For sure, back then, Microsoft’s EconML was in its early stages, and in subsequent years, several companies like Uber, Meta, and Amazon began developing their own Python packages. In 2022, I went to Stanford and talked with Professor Susan Athey about translating her Causal Inference and Machine Learning bookdown into Python. Doing this taught me a lot about various methods for heterogeneous treatment effects, such as causal trees and forests, and the intersection of reinforcement learning and causal inference. During my time in the Bay Area, I was impressed by the close collaboration between academia and big tech companies like Uber, Roblox, and Amazon. Academia focuses on developing these methods, while tech companies apply them in practice.
Kevin: Rodrigo, you also have quite the varied background. Could you share a bit about your path into working on data science, causal inference, and software engineering?
Rodrigo: Same as Alexander, I started off as an economist. I love the topic of economics overall, and during my undergrad I also became really interested in software development. At some point, one of the variable topic courses in the faculty was going to cover ML methods and their applications to the social sciences, which piqued my interest. This class was taught by Pavel Coronado, the head of the AI laboratory for Social Sciences at the faculty. He informed us that the laboratory would be starting a graduate diploma program on ML and AI for Social Sciences next semester. I was given the opportunity of joining this program before finishing my undergrad. During this program, I was able to really broaden my knowledge on topics like object-oriented programming, neural networks, big data, etc.; some of these topics were taught by Alexander. Near the end of the program, Alexander was looking for assistants with a good handle on software development for data science. Since then, I have collaborated with the team on a variety of projects.
Kevin: That’s wonderful, sounds like you both benefited from learning software development and applying those skills by engaging with instructors who believed in you (and/or were desperate for help!). Finding a niche that you’re passionate about is such a joy, and I’m curious about how you’ve found living in that niche. What’s the day-to-day like for you both?
Alexander: I work full-time for the World Bank, where I spend most of my time doing econometric analysis using administrative data. We use rich digital transfer data to analyze quasi-experiments, with most of this data coming from countries in South Asia like Pakistan, Bangladesh, and India. The other half of my time, I work with different professors. I have a team called, Dive Into Causal Machine Learning, which Rodrigo is also part of. We focus on creating causal ML packages in Python so that people from industry and government can use them for free. Currently, I am collaborating with Nathan Kallus (Cornell Tech/Netflix) on the intersection of reinforcement learning and causal inference, with Damian Clarke (U. Chile) on the SDID algorithm, and with Pedro Sant’Anna on DiD with multiple time periods package.
Rodrigo: Most of my work is with Alex and D2CML, so I get to be involved in a variety of projects ranging from teaching materials for undergraduate and graduate students to AI applications and academic research. I also do some related freelance work, and I have some open source passion projects.
Kevin: Have things changed since generative AI tooling came along? Have you found generative AI tools to be helpful?
Alexander: When I started creating econometric packages, most of my work was translating code from Stata and R to Python. There were no LLMs, so depending on the package it could take approximately two/three months. Once ChatGPT appeared, it was really helpful for translating code. I think that we can now do the translation twice as fast. However, I should say it works better for Python than for Julia’s translation. What I have learned now is how to ask good questions. A lot of the work for panel datasets is preprocessing big datasets, and for that, you have to be a good prompt engineer to be precise with the questions you formulate. I would like to try GitHub Copilot because I believe it could optimize my algorithms more effectively. Reviewing all the scripts with ChatGPT sometimes can be quite tedious.
Rodrigo: I have definitely found generative AI helpful. The way I use it is that it gives me an overall structure or a starting point for a task, and I take things from there. For example, I’m a very indecisive writer, so prompting a generative AI tool with an overall topic and some guidelines tends to give me the starting point I need, which really enhances my productivity even when the final product is completely different from the initial generative AI response. Things have definitely changed with AI tools: one notable example is the amount of students that use generative AI tools for their assignments. I think some effort goes into generating good responses with AI, and making sure that the responses are appropriate. So, instead of banning the use of generative AI, I think it’s best to become very familiar with it. I believe being a good prompt engineer will be an extremely useful skill in the near future.
Kevin: Advice you might have for folks who are starting out in software engineering or research? What tips might you give to a younger version of yourself, say, from 10 years ago?
Alexander: For those starting in software engineering or research, here’s my advice. Take an algorithms course, preferably in C++, as it provides a solid foundation for learning any programming language and is crucial for data processing and econometric implementation. Focus on mastering linear algebra; understanding matrix decomposition and optimization methods will make creating packages much easier. Learn Git and GitHub to become proficient in version control and teamwork. Additionally, take courses in causal inference and machine learning; these are now accessible to undergraduates and are essential for modern research. For those heading to graduate school, studying reinforcement learning and its integration with causal inference is highly beneficial, as these techniques are increasingly used in tech companies for data analysis.
Rodrigo: For both software engineering and research, starting out can be overwhelming because there is a lot you don’t know. We can also fall into “optimization paralysis” when we try to figure out the optimal course of action. For the first problem, sometimes it is enough to immerse yourself in the knowledge without trying too hard to understand it, and the understanding comes by itself like learning a language through immersion. For the second problem, some degree of impulsiveness can be very helpful, funnily enough; build an intuition and trust it.
Kevin: Learning resources you might recommend to someone interested in learning more about this space?
Alexander: For sure, this is the list for future causal ML researchers.
- The Book of Why by Judea Pearl
- Causal Inference: The Mixtape by Scott Cunningham
- The Effect by Nick Huntington-Klein
- Applied Causal Inference Powered by ML and AI by Victor Chernozhukov et al
- Machine Learning and Causal Inference: A Short Tutorial by Guido W. Imbens and Susan Athey
- Awesome Causal Inference by Matteo Courthoud
- Dive into Causal Machine Learning ( self promotion 😉 )
Rodrigo: Right now my favorite resource for this topic is Applied Causal Inference Powered by ML and AI by Chernozhukov, Hansen, Kallus Spindler, and Syrgkanis. I also like having an introductory econometrics textbook by hand; Introductory Econometrics: A Modern Approach by Jeffrey M. Wooldridge is a really good resource in this regard.
Kevin: Thank you, Alexander and Rodrigo! It’s been fascinating to learn about your current work and broader career trajectory. We truly appreciate you taking the time to speak with us and will absolutely keep following your work, where we hope the Innovation Graph can continue to serve as a helpful resource.
The post How researchers are using GitHub Innovation Graph data to estimate the impact of ChatGPT appeared first on The GitHub Blog.
]]>