Are you already using code scanning autofix?
The post Automating open source: How Ersilia distributes AI models to advance global health equity appeared first on The GitHub Blog.
]]>Taking an average of 10 years and $1.3 billion to develop a single new medication, pharmaceutical companies often focus their drug discovery efforts on a high return on investment, developing drugs for diseases prevalent in high-income countries—and leaving lower- and middle-income countries behind.
In response, investments in building AI/ML models for drug discovery have soared in the last five years. By using these models, scientists can shorten their research and development timeline by getting better at identifying drug prospects. However, access to these models is limited by data science expertise and computational resources.
The nonprofit Ersilia Open Source Initiative is tackling this problem with the Ersilia Model Hub.
Through the hub, Ersilia aims to disseminate AI/ML models and computational power to researchers focused on drug discovery for infectious diseases in regions outside of Europe and North America.
In this post, we’ll share how Ersilia and GitHub engineers built a self-service IssueOps process to make AI/ML models in the hub publicly available, allowing researchers to find and run them for free on public repositories using GitHub Actions. 👇
Ersilia Model Hub: What it is and who uses it
Though largely overlooked by for-profit pharmaceutical companies, research on infectious diseases in low- and middle-income countries is ongoing. The hub taps into that research by serving as a curated collection of AI/ML models relevant to the discovery of antibiotic drugs.
Through its platform, Ersilia helps to disseminate published findings and models, as well as their own, through public repositories on GitHub so undersourced researchers and institutions can use them for free to improve drug discovery in their respective countries.
“At some point, I realized that there was a need for a new organization that was flexible enough to actually travel to different countries and institutions, identify their data science needs, which are often critically lacking, and develop some data science tools,” says Ersilia co-founder, Miquel Duran-Frigola, PhD.
That realization crystallized into Ersilia and the Ersilia Model Hub, which Duran-Frigola founded with two other biomedicine experts, Gemma Turon, PhD, and Edo Gaude, PhD.
“The hub contains computational models, which are relatively very cheap to run compared to doing experiments in the laboratory,” Duran-Frigola says. “Researchers can create simulations using computational models to predict how a candidate molecule might treat a particular disease. That’s why these models are often good starting points to perform drug discovery research.”
Currently, there are about 150 models in the Ersilia Model Hub.
Who uses and contributes to Ersilia?
Most of the contributors who add models to the hub are data scientists and software developers, while most who run those models are researchers in biomedicine and drug discovery at institutions in various countries throughout Sub-Saharan Africa. Over the next two years, Ersilia aims to establish the hub in 15 institutions throughout Africa.
Ersilia’s biggest partner is the University of Cape Town’s Holistic Drug Discovery and Development (H3D) Centre (H3D) Centre. Founded in 2010 as Africa’s first integrated drug discovery and development center, H3D researchers use the data science tools disseminated by the Ersilia Model Hub to advance innovative drug discovery across the African continent.
Ersilia is also partnering with emerging research centers, such as the University of Buea’s Center for Drug Discovery in Cameroon. A fellowship from the Bill & Melinda Gates Foundation provided the center with the seed funding it needed to start in 2022, and today it has 25 members.
“The center aims to discover new medicines based on natural products collected from traditional healers, but it doesn’t have a lot of resources yet,” explains Duran-Frigola. “The idea is that our tool will become a core component of the center so its researchers can benefit from computational predictions.”
How the Ersilia Model Hub works
Contributors can request a model be added to the hub by opening an issue.
The vast majority of models are open source, all are publicly available, and most are submitted and pulled from scientific literature. For example, biochemists at the David Braley Centre for Antibiotic Discovery created an ML model to predict how likely a chemical compound will inhibit the activity of Acinetobacter baumannii, a pathogen often transmitted in healthcare settings and known for its resistance to multiple antibiotics.
But Ersilia develops some models in-house, like one that predicts the efficacy of chemicals against lab-grown Mycobacterium tuberculosis (M. tuberculosis), using data from Seattle Children’s Hospital. M. tuberculosis is the agent that causes tuberculosis, an infectious disease that primarily affects individuals in low- and middle-income countries.
While the Ersilia team manually approves which models enter the hub, it uses GitHub Actions to streamline requests and solicit the following information from model contributors:
- The model’s schema (what input is expected and what output will be returned).
- Open source license information.
- Whether the model can run on CPUs or GPUs.
- Link to model’s open source code.
- Link to publication (either peer-reviewed or preprint).
- Labels to describe the model’s use case, with tags like malaria, classification, regression, unsupervised, or supervised.
When Ersilia approves the model, the contributor submits a pull request that triggers a set of tests. If all those tests are successful, GitHub Actions merges the pull request and the model is incorporated into the hub.
Rachel Stanik, a software engineer at GitHub, breaks down the steps to adding an AI model to the Ersilia Model Hub:
From the user side, researchers interested in drug discovery can fetch static and ready-to-use AI/ML models from the hub and contained in public repositories, input candidate molecules, and then receive predictions that indicate how well the candidate molecule performs against a specific disease—all online and for free. The self-service process contains an important note on privacy, disclosing that any activity on the repository is open and available to the general public—which includes those predictions, stored as actions artifacts.
“Right now, Ersilia is focused on information and tool dissemination,” says Duran-Frigola. “For the future, we’re working on providing a metric of confidence for the models. And, with a bigger user base, Ersilia could aggregate inputs to capture the candidate molecules that people are testing against infectious diseases.”
Using an aggregation of candidate molecules, researchers could glean which drugs are available in certain countries and experiment with repurposing those drugs to fight against other microbes. The information could help them to treat neglected diseases without having to develop a new drug from scratch.
How GitHub built a self-service process for the Ersilia Model Hub
Before reaching out to GitHub, researchers couldn’t independently access or run the models in the hub.
GitHub customer success architect, Jenna Massardo, and social impact engineer, Sean Marcia, who’s also the founder of the nonprofit Ruby For Good, worked with Ersilia to fix that by creating a self-service process for the hub. GitHub’s Skills-Based Volunteer program, run by GitHub’s Social Impact team, organized the opportunity. The program partners employees with social sector organizations for a period of time to help solve strategic and technical problems.
Creating an IssueOps process
Massardo and Marcia’s first step in problem-solving was understanding and learning how the software works: How would a researcher share information? What kind of outputs should a researcher expect?
“I had them walk me through the process of setting up and using the Ersilia Model Hub on my workstation. It was only once it was running on my workstation, where I could actually test it and do the process myself, that I began to pick it apart,” Massardo says.
Massardo and Marcia then broke the phases into pieces: How would a researcher make a request to use a model? How would the model process the researcher’s input data? How would that input be handled? What notifications would researchers get?
Massardo and Marcia decided to bring in a standard IssueOps pattern, which uses GitHub issues to drive automation with GitHub Actions.
“It’s a super common pattern. A lot of our internal tooling at GitHub is built on it, like some of our migration tooling for our enterprise customers,” Massardo explains. She quickly ruled out using a pull request flow, where collaborators propose changes to the source code.
“People are contributing to the repository but they’re not actually making code changes. They’re just adding files for processing,” Massardo says. “Using pull requests would have meant a lot of noise in the repository’s history. But issues are perfect for this sort of thing.”
Once a plan was set in place, Massardo began to build while Marcia kept the collaboration running smoothly.
Researchers, biologists, and even students can now use the self-service process by simply going to the hub, creating an issue, filling out the template, and submitting it. Note, the template requires users to select the model they want to run and input candidate molecule(s) in standard SMILES format (Simplified Molecular Input Line Entry System), a computer-readable format to represent complex molecules and text.

Setting up a GitHub Actions workflow
Originally, Ersilia wanted to build a custom GitHub Action, but Massardo—someone who’s written multiple custom actions used internally and externally—knew that it comes with a fair amount of maintenance.
“There’s a lot of code you’re writing on your own, and that means you have to manage a bunch of dependencies and security updates,” Massardo says. “At that point, it becomes a full application.”
Understanding the problem as a series of individual tasks allowed her to scope an effective and cost-efficient solution.
“We created a series of simple workflows using readily available actions from GitHub Marketplace and just let GitHub Actions do its thing,” Massardo says. “By understanding Ersilia’s actual desires and needs, we avoided overcomplicating and obfuscating the issue.”
When a researcher files an issue to run a candidate molecule through a model, it triggers a GitHub Actions workflow to run. Here’s a look at the process:
- GitHub Actions spins up a GitHub-hosted runner to execute the workflow.
- The GitHub Issue Forms Body Parser action, parses the content out of the issue and translates it from Markdown into structured, usable data.
- The workflow fetches the user-requested model and then triggers Ersilia’s software to run.
- Ersilia’s software configures the model, and the user-provided input is put into a file that the model can process.
- Ersilia’s software then generates a CSV output, saved as an artifact in GitHub Actions.
- The workflow lets the user know that it was successfully completed by leaving a comment in the open issue, which includes a link to the artifact that the user can click to download.
- This particular workflow has a 30-day retention period, so five days before the artifact expires, stale bot notifies users to download the output. After 30 days, stale bot automatically closes the issue.
“Everything happens right on GitHub,” Massardo explains. “The user doesn’t have to worry about anything. They just submit the issue, and Ersilia’s workflow processes it and lets them know when everything’s done. Importantly, the Ersilia staff, who are busy running the nonprofit, don’t have to do any maintenance.”
Using Docker containers to run AI models on GitHub runners
To streamline the process of creating model images, Ersilia uses a Dockerfile template. When a researcher submits a new model to the hub, Ersilia copies the template to the model’s repository, which kicks off the Docker image build for that model—a process that’s powered by GitHub-hosted runners. Once built, the model image lives in the hub and researchers can run it as many times as needed. A model can also be rebuilt if fixes are needed later.
The models in the hub are available in public repositories, where GitHub Actions runs at no cost. When researchers use the self-service process, GitHub Actions runs these Docker images on GitHub’s runners for free, which in turn allows researchers to run these models for free. Models in the hub are also designed and optimized to run on CPUs so that researchers can run the models locally on their machines, making them more accessible to the global scientific community.
The models aren’t very large, explains Ersilia CTO, Dhanshree Arora, because they’re built for very specific use cases. “We’re actively working to reduce the size of our model images, so they use less network resources when transferred across machines, occupy less space on the machine where they run, and enable faster spin-up times for the containers created from these model images,” Arora says.
The ability to package these models as Docker containers also means that researchers can collaborate more easily, as the models run in consistent and reproducible environments.
Automating daily model fetching
When researchers file an issue to use a model, they see a list of available models. That list is updated every day by a workflow that Massardo built using GitHub Actions and some custom code.
Every day, the workflow:
- Fetches the file containing the list of models managed by the Ersilia team. The file is automatically updated whenever the team modifies or deprecates a model, or adds a new model.
- Runs a Python script to process the file and pull out data that captures new, updated, or deprecated models.
- Updates the list of models in the issues template with the extracted data.
“This is another example of how we built this process to be as hands-off as possible while still making it as easy as possible for researchers to actually use the tool,” Massardo says.
Ersilia wants your contributions
Ersilia has grown an open source community of contributors and users, and believes that everything it does needs to continue to be open source. It was initially drawn to GitHub Actions because it’s free to use in public repositories. After witnessing the impact of GitHub Actions on the model hub, Duran-Frigola wants to identify more use cases.
“I want to find creative ways to use GitHub Actions, beyond CI/CD, to help more researchers use our tools,” he says.
He also wants Ersilia’s many interns to practice using GitHub Copilot and gain hands-on experience with using AI coding tools that are changing the landscape of software development.
3 tips for contributing to open source projects, from a Hubber
➡️ Read Massardo’s three tips for contributing to open source projects, Ersilia’s contributions guidelines, then start engaging with GitHub’s open source community.
- Find a project that interests you. Working on a project that’s personally interesting generally means you’ll stick with it and not get bored.
- Look through the issues in a project’s repository to find something that you can fix or add. A lot of projects use the
good first issuelabel to identify things that newcomers can tackle. - Be prepared to iterate. Some project owners require several smaller contributions before they’ll entertain a larger product change. Some folks are in different parts of the world so you may need to rewrite things to be more clear. If you’re thinking about a major change to a project, open an issue to discuss it with the owners first because they might have a different vision.
Contribute to another nonprofit using For Good First Issue
Ersilia was recently designated as a Digital Public Good (DPG) by the United Nations. DPGs are open source solutions—ranging from open source software and data to AI systems and content collections—that are designed to unlock a more equitable world. DPGs are freely accessible, intended to be used and improved by anyone to benefit the public, and they’re designed to address a societal challenge and promote sustainable development.
If you’re inspired by Ersilia and want to contribute to more DPGs, check out GitHub’s For Good First Issue, a curated list of recognized DPGs that need contributors.
For Good First Issue is designed as a tool for nonprofits to connect with technologists around the world. As nonprofits often lack funding and resources to solve society’s challenges through technology, For Good First Issue can connect nonprofits that need support with the people who want to make positive change.
More reading on Ersilia, GitHub Actions, and For Good First Issue
- AI can help to tailor drugs for Africa—but Africans should lead the way
- Ongoing implementation and prospective validation of artificial intelligence/machine learning tools at an African drug discovery center
- For Good First Issue: Introducing a new way to contribute
- Understanding GitHub Actions
The post Automating open source: How Ersilia distributes AI models to advance global health equity appeared first on The GitHub Blog.
]]>The post Unlocking the power of unstructured data with RAG appeared first on The GitHub Blog.
]]>Whether they’re building a new product or improving a process or feature, developers and IT leaders need data and insights to make informed decisions.
When it comes to software development, this data exists in two ways: unstructured and structured. While structured data follows a specific and predefined format, unstructured data—like email, an audio or visual file, code comment, or commit message—doesn’t. This makes unstructured data hard to organize and interpret, which means teams can miss out on potentially valuable insights.
To make the most of their unstructured data, development teams are turning to retrieval-augmented generation, or RAG, a method for customizing large language models (LLMs). They can use RAG to keep LLMs up to date with organizational knowledge and the latest information available on the web. They can also use RAG and LLMs to surface and extract insights from unstructured data.
GitHub data scientists, Pam Moriarty and Jessica Guo, explain unstructured data’s unique value in software development, and how developers and organizations can use RAG to create greater efficiency and value in the development process.
Unstructured data in software development
When it comes to software development, unstructured data includes source code and the context surrounding it, as these sources of information don’t follow a predefined format.
Here are some examples of unstructured data on GitHub:
- README files describe in text the purpose behind project source code, and include instructions for source code use, how to contribute, and other details that developers decide is important to include. While they’re usually written in Markdown, README files don’t follow a predefined structure.
- Code files are more orderly than README files in that they follow the syntax of a programming language. But not all code files have the exact same fields nor are they all written in the same format. Additionally, some parts of the file, like coding logic and variable names, are decided by individual developers.
- Package documentation explains how the software works and how to use it. Documentation, written in natural language, can include installation instructions, troubleshooting tips, a description of the package’s API, and a list of any dependencies required to use the package. It can also include code snippets that highlight the package’s features.
- Code comments explain the function behind certain code blocks in a code file. They’re text comments written in natural language and make the source code easier to understand by other developers.
- Wiki pages, while not limited to unstructured data, can contain helpful text documentation about installation instructions, API references, and other information.
- Commit messages describe in natural language text the changes a developer made to a codebase and why.
- Issue and pull request descriptions are written in natural language and in a text field. They can contain any kind of information a developer chooses to include about a bug, feature request, or general task in a project.
- Discussions contain a wealth and variety of information, from developer and end- user feedback to open-ended conversations about a topic. As long as a repository enables discussions, anyone with a GitHub account can start a discussion.
- Review comments are where developers can discuss changes before they’re merged into a codebase. Consequently, they contain information in natural language about code quality, context behind certain decisions, and concerns about potential bugs.
The value of unstructured data
The same features that make unstructured data valuable also make it hard to analyze.
Unstructured data lacks inherent organization, as it often consists of free-form text, images, or multimedia content.
“Without clear boundaries or predefined formats, extracting meaningful information from unstructured data becomes very challenging,” Guo says.
But LLMs can help to identify complex patterns in unstructured data—especially text. Though not all unstructured data is text, a lot of text is unstructured. And LLMs can help you to analyze it.
“When dealing with ambiguous, semi-structured or unstructured data, LLMs dramatically excel at identifying patterns, sentiments, entities, and topics within text data and uncover valuable insights that might otherwise remain hidden,” Guo explains.
| Need a refresher on LLMs? Check out our AI explainers, guides, and best practices > |
Here are a few reasons why developers and IT leaders might consider using RAG-powered LLMs to leverage unstructured data:
- Surface organizational best practices and establish consistency. Through RAG, an LLM can receive a prompt with additional context pulled from an organization’s repositories and documents. So, instead of sifting through and piece-mealing documents, developers can quickly receive answers from an LLM that align with their organization’s knowledge and best practices.
-
Accelerate and deepen understanding of an existing codebase—including its conventions, functions, common issues, and bugs. Understanding and familiarizing yourself with code written by another developer is a persisting challenge for several reasons, including but not limited to: code complexity, use of different coding styles, a lack of documentation, use of legacy code or deprecated libraries and APIs, and the buildup of technical debt from quick fixes and workarounds.
RAG can help to mediate these pain points by enabling developers to ask and receive answers in natural language about a specific codebase. It can also guide developers to relevant documentation or existing solutions.
Accelerated and deepened understanding of a codebase enables junior developers to contribute their first pull request with less onboarding time and senior developers to mitigate live site incidents, even when they’re unfamiliar with the service that’s failing. It also means that legacy code suffering from “code rot” and natural aging can be more quickly modernized and easily maintained.
Unstructured data doesn’t just help to improve development processes. It can also improve product decisions by surfacing user pain points.
Moriarty says, “Structured data might show a user’s decision to upgrade or renew a subscription, or how frequently they use a product or not. While those decisions represent the user’s attitude and feelings toward the product, it’s not a complete representation. Unstructured data allows for more nuanced and qualitative feedback, making for a more complete picture.”
A lot of information and feedback is shared during informal discussions, whether those discussions happen on a call, over email, on social platforms, or in an instant message. From these discussions, decision makers and builders can find helpful feedback to improve a service or product, and understand general public and user sentiment.
What about structured data?
Contrary to unstructured data, structured data—like relational databases, Protobuf files, and configuration files—follows a specific and predefined format.
We’re not saying unstructured data is more valuable than structured. But the processes for analyzing structured data are more straightforward: you can use SQL functions to modify the data and traditional statistical methods to understand the relationship between different variables.
That’s not to say AI isn’t used for structured data analysis. “There’s a reason that machine learning, given its predictive power, is and continues to be widespread across industries that use data,” according to Moriarty.
However, “Structured data is often numeric, and numbers are simply easier to analyze for patterns than words are,” Moriarty says. Not to mention that methods for analyzing structured data have been around longer** **than those for analyzing unstructured data: “A longer history with more focus just means there are more established approaches, and more people are familiar with it,” she explains.
That’s why the demand to enhance structured data might seem less urgent, according to Guo. “The potential for transformative impact is significantly greater when applied to unstructured data,” she says.
How does RAG extract value from unstructured data?
With RAG, an LLM can use data sources beyond its training data to generate an output.
RAG is a prompting method that uses retrieval—a process for searching for and accessing information—to add more context to a prompt that generates an LLM response.
This method is designed to improve the quality and relevance of an LLM’s outputs. Additional data sources include a vector database, traditional database, or search engine. So, developers who use an enterprise AI tool equipped with RAG can receive AI outputs customized to their organization’s best practices and knowledge, and proprietary data.
We break down these data sources in our RAG explainer, but here’s a quick summary:
- Vector databases. While you code in your IDE, algorithms create embeddings for your code snippets, which are stored in a vector database. An AI coding tool can search that database to find snippets from across your codebase that are similar to the code you’re currently writing and generate a suggestion.
And when you’re engaging with GitHub Copilot Chat on GitHub.com or in the IDE, your query or code is transformed into an embedding. Our retrieval service then fetches relevant embeddings from the vector database for the repository you’ve indexed. These embeddings are turned back into text and code when they’re added to the prompt as additional context for the LLM. This entire process leverages unstructured data, even though the retrieval system uses embeddings internally.
- General text search. When developers engage with GitHub Copilot Chat under a GitHub Copilot Enterprise plan, they can index repositories—specifically code and documentation. So, when a developer on GitHub.com or in the IDE asks GitHub Copilot Chat a question about an indexed repository, the AI coding tool can retrieve data from all of those indexed, unstructured data sources. And on GitHub.com, GitHub Copilot Chat can tap into a collection of unstructured data in Markdown files from across repositories, which we call knowledge bases.
Learn about GitHub Copilot Enterprise features >
But wait, why is Markdown considered unstructured data? Though you can use Markdown to format a file, the file itself can contain essentially any kind of data. Think about it this way: how would you put the contents of a Markdown file in a table?
- External or internal search engine. The retrieval method searches and pulls information from a wide range of sources from the public web or your internal platforms and websites. That information is used for RAG, which means the AI model now has data from additional files—like text, image, video, and audio—to answer your questions.
Retrieval also taps into internal search engines. So, if a developer wants to ask a question about a specific repository, they can index the repository and then send their question to GitHub Copilot Chat on GitHub.com. Retrieval uses our internal search engine to find relevant code or text from the indexed files, which are then used by RAG to prompt the LLM for a contextually relevant response.
Stay smart: LLMs can do things they weren’t trained to do, so it’s important to always evaluate and verify their outputs.
Use RAG to unlock insights from unstructured data
As developers improve their productivity and write more code with AI tools like GitHub Copilot, there’ll be even more unstructured data. Not just in the code itself, but also the information used to build, contextualize, maintain, and improve that code.
That means even more data containing rich insights that organizations can surface and leverage, or let sink and disappear.
Developers and IT leaders can use RAG as a tool to help improve their productivity, produce high-quality and consistent code at greater speed, preserve and share information, and increase their understanding of existing codebases, which can impact reduced onboarding time.
With a RAG-powered AI tool, developers and IT leaders can quickly discover, analyze, and evaluate a wealth of unstructured data—simply by asking a question.
A RAG reading list 📚
- What is retrieval-augmented generation, and what does it do for generative AI?
- Customizing and fine-tuning LLMs: What you need to know
- How we’re experimenting with LLMs to evolve GitHub Copilot
- How GitHub Copilot is getting better at understanding your code
The post Unlocking the power of unstructured data with RAG appeared first on The GitHub Blog.
]]>The post How AI enhances static application security testing (SAST) appeared first on The GitHub Blog.
]]>In a 2023 GitHub survey, developers reported that their top task, second only to writing code (32%), was finding and fixing security vulnerabilities (31%).
As their teams “shift left” and integrate security checks earlier into the software development lifecycle (SDLC), developers have become the first line of defense against vulnerabilities.
Unfortunately, we’ve found that “shifting left” has been more about shifting the burden of security practices to developers, rather than their benefits. But with AI, there’s promise: 45% of developers think teams will benefit from using AI to facilitate security reviews. And they’re not wrong.
We spoke with Tiferet Gazit, the AI lead for GitHub Advanced Security, and Keith Hoodlet, principal security specialist at GitHub, to discuss security pain points for developers, the value of using an AI-powered security tool, and how AI enhances static application security testing (SAST).
Why are developers frustrated with security?
Before sharing insights from Gazit and Hoodlet, let’s hear from developers directly.
In late 2019, Microsoft’s One Engineering System team sat down with a handful of developers to understand their frustrations with following security and compliance guidelines. Though that was a few years ago, their pain points still resonate today:
- When conducting security reviews, some developers are forced to use tools that weren’t designed for them, which negatively impacts their ability to find and address security vulnerabilities.
- Also, the priority for most developers is to write and review code. Yet, in the age of shifting left, they’re also expected to review, understand, and remediate vulnerabilities as part of their day-to-day responsibilities.
When developers execute a program, they have everything they need in a run-time environment. Completing a security review is less straightforward. Often, developers need to exit their IDEs to view vulnerability alerts, research vulnerability types online, and then revisit their IDEs to address the vulnerability. This is what we call context-switching, and it can increase cognitive load and decrease productivity.
In short, security isn’t an inherent part of the development process, and developers often feel less confident in how secure their code is.
Without intervention, these frustrations will only increase over time. 75% of enterprise software engineers are expected to use AI coding assistants by 2028, according to Gartner. That means as developers improve their productivity and write more code with AI tools like GitHub Copilot, there will be even more code to review.
Security experts are stretched thin, too
It’s typically reported that for every 100 developers, there’s one security expert who ends up being the last line of defense against vulnerabilities (and is responsible for setting and enforcing security policies), which is a significant undertaking. While the exact numbers might vary, the ISC2 (International Information System Security Certification Consortium) reported a demand for four million more security professionals in its 2023 workforce study.
While AI doesn’t replace security experts, it can help them augment their knowledge and capabilities, especially when their expertise is in high demand.
“AI can help with those code and security reviews to ensure that increased momentum doesn’t lead to increased vulnerabilities,” Gazit says.
How AI enhances SAST tools
SAST tools aren’t the only kind of security tool used by developers, but they’re one of the most popular. Let’s look at how AI can help SAST tools do their job more efficiently.
Increased vulnerability detection
In order for SAST tools to detect vulnerabilities in code, they need to be shown what to look for. So, security experts use a process called modeling to identify points where exploitable user-controlled data enters and flows throughout a codebase. But given how often those components change, modeling popular libraries and frameworks is hard work.
That’s where AI comes in.
Security teams are experimenting with AI to model an extensive range of open source frameworks and libraries, improving the teams’ understanding of what’s inside of each software component.
Watch how Nick Liffen, director of GitHub Advanced Security, and Niroshan Rajadurai, VP of GTM strategy for AI and DevSecOps, show how AI could model unknown packages.
Contextualized vulnerabilities directly in a workspace
Code scanning autofix is an example of an AI-powered security feature that combines a SAST tool—in this case, GitHub’s CodeQL—with the generative AI capabilities of GitHub Copilot.
With code scanning autofix, developers receive an AI-suggested code fix alongside an alert directly in a pull request. Then, they get a clear explanation of the vulnerability and the fix suggestion, specific to their particular use case. To view and apply autofix suggestions directly in the CLI, they can enable the GitHub CLI extension.
In its first iteration, code scanning autofix analyzes and suggests fixes in JavaScript, TypeScript, Python, Java, C#, and Go. It can generate a fix for more than 90% of vulnerability types—and over two-thirds of those fixes can be merged with little to no edits. More languages like C++ and Ruby will be supported in the future.
The payoff is that developers can remediate vulnerabilities faster and in their workflows, rather than catching those vulnerabilities later in production.
A fortified SDLC
Developers use SAST tools to protect their code throughout the SDLC.
Once developers enable a code scanning solution like CodeQL, the SAST tool will scan your source code, integrating security checks as part of their CI/CD workflow:
- When you make changes to a codebase and create pull requests on GitHub, CodeQL will automatically conduct a full scan of your code as if the pull request was merged. It will then alert you if a vulnerability is found in the files changed in the pull request.
That means developers have the ability to continuously monitor the security posture of their source code as modules come together—even before changes are merged to their main branch. As a result, developers can remediate vulnerabilities right away, in development, and before their code is sent to production.
-
Outside of commits and pull requests, you can also set CodeQL to run at specified times in your GitHub Actions workflow. So, if you want CodeQL to regularly scan your code at specific time intervals, you can schedule that using a GitHub Actions workflow.
See code scanning autofix in action
“Autofix makes CodeQL friendlier for developers by suggesting a fix and providing contextual explanations of the vulnerability and its remediation,” Gazit says. “This use of AI lowers the barrier of entry for developers who are tasked with fixing vulnerabilities.”
Let’s say a bad actor inserts a SQL injection into your application. The SQL injection enters your codebase through a user input field, and if the code comprising the injection exploits unintentional vulnerabilities, then the bad actor gets unauthorized access to sensitive data in your application.
SQL injections are a common type of vulnerability often found with a SAST tool.
Here’s a step-by-step look at how code scanning autofix, powered by GitHub Copilot, would detect a SQL injection and then surface it in an alert with an AI-suggested fix.

Step 1: Hunt for vulnerabilities. Code scanning with CodeQL can be enabled for free on all public repositories and scheduled to run automatically. The scanning process has four main parts, all centered around your source code: tokenization, abstraction, semantic analysis, and taint analysis. Here’s a detailed breakdown of each of those steps.
In short, tokenizing your source code standardizes it, and that allows CodeQL to analyze it later. Abstracting your source code transforms your lines of code into a hierarchical structure that shows the relationship between those lines of code. Semantic analysis uses that abstraction to understand the meaning of your source code.
Finally, taint analysis looks at the way your source code handles user input data. It identifies data sources (where input data enters the source code), flow steps (where data is passed through the code), sanitizers (functions that make input data safe), and sinks (functions that if called with unsanitized data could cause harm). Advanced SAST tools like CodeQL can evaluate how well input data is sanitized or validated, and decide from there whether to raise the path as a potential vulnerability.
Step 2: Construct a prompt to generate a fix. For all languages supported by CodeQL, developers will see a SQL injection alert surfaced in a pull request in their repository, along with a natural language description of the vulnerability and contextual documentation. These alerts will also include a suggested fix that developers can accept, edit, or dismiss.
Here’s what’s included in the prompt, that’s sent to GitHub Copilot, to generate the enhanced alert:
- The initial CodeQL alert and general information about the type of vulnerability detected. This will usually include an example of the vulnerability and how to fix it, extracted from the CodeQL query help.
-
Code snippets and line numbers, potentially from multiple source-code files, along the data flow identified during CodeQL’s taint analysis. These code snippets signal the places where edits are most likely needed in your source.
To guide the format of GitHub Copilot’s response, our machine learning engineers:
- Constrain GitHub Copilot’s underlying model to only edit the code included in the prompt.
- Ask the model to generate outputs in Markdown, including a detailed natural language explanation of the vulnerability and the suggested fix.
- Ask for “before” and “after” code blocks, demonstrating the snippets that require changes (including some surrounding context lines) and the edits to be made.
- Instruct the model to list any external dependencies used in the fix, such as data sanitization libraries.
Step 3: Check for undesirable code. Code snippets that match or nearly match runs of about 150 characters of public code on GitHub are then filtered from AI-generated coding suggestions. Vulnerable code, and off-topic, harmful, or offensive content are also filtered out.
You can explore the GitHub Copilot Trust Center to learn more about GitHub Copilot’s filters and responsible data handling.
Step 4: Apply finishing touches. Before developers see GitHub Copilot’s suggested fix, a fix generator processes and refines the LLM output to detect and correct any small errors.
The fix generator does this by:
- Conducting a fuzzy search to ensure the “after” code blocks and line numbers, which contain the AI-generated suggested code fixes, match the “before” code blocks and line numbers. A fuzzy search looks for exact and similar matches between the code blocks, so the fix generator can catch and correct small errors, like those related to indentation, semicolon, or code comment differences between the two code blocks.
- Using a parser to check for syntax errors.
- Conducting semantic checks to evaluate the logic of the AI-suggested code fix. Name-resolution and type checks, for example, help ensure that the suggested code matches and maintains the intention and functionality of the original code.
- Verifying any dependencies suggested by GitHub Copilot. This means locating the relevant configuration file containing information about the project’s dependencies to see if the needed dependency already exists in the project. If not, the fix generator verifies that the suggested dependencies exist in the ecosystem’s package registry, and checks for known vulnerable or malicious packages. It then adds new and needed dependencies to the configuration file as part of the fix suggestion.
Step 5: Explain the vulnerability and suggested fix. The final step is to surface the CodeQL alert to developers in a pull request. With code scanning autofix, the original CodeQL alert is enhanced with an AI-suggested fix, a natural language explanation of the vulnerability and suggested fix, and a diff patch. Developers can accept the suggested edit as is, refine the suggested edit, or dismiss it.

How developers, the SDLC, and organizations benefit from AI-powered SAST tools
With AI, security checks have the ability to smoothly integrate into a developer’s workflow, making security a feature of the SDLC rather than an afterthought dealt with in production. When developers can help secure code more easily in the development phase, the SDLC as a whole is hardened. And when the SDLC is better protected, organizations can focus more on innovation.
“When you treat security as a feature of the SDLC, your applications become more robust against increasingly complex attacks, which saves you time and money,” Hoodlet says. “You can direct those saved costs towards other improvements and experimentation with new features. The result? Organizations build a reputation for building secure products while freeing up resources for innovation.” Additionally, security teams are free to focus on the strategic initiatives that deserve their expertise.
Organizations that adopt AI-enhanced SAST tools can help developers to feel supported and productive in their security practices, so that developers can:
- Help secure more code in development. Just look at the numbers. Code scanning autofix powered by GitHub Copilot can generate a fix for more than 90% of vulnerability types detected in your codebase, and more than two-thirds of its suggestions can be merged with little to no edits.
-
Become faster and better at remediating vulnerabilities. Through code scanning autofix, developers are given natural language explanations about an AI-generated code fix. They’re also given a description of the detected vulnerability that’s tailored to its detection in a specific codebase, rather than a general one. This specific context helps developers to better understand the nature of a detected vulnerability, why it exists in a codebase, and how to fix it.
-
Receive security guidance directly in their workspace. Developers receive all the benefits of an AI-enhanced SAST tool directly in a pull request. Unlike traditional security tools, this one is made for them.
Looking to secure your organization with the power of AI?
The post How AI enhances static application security testing (SAST) appeared first on The GitHub Blog.
]]>The post What is retrieval-augmented generation, and what does it do for generative AI? appeared first on The GitHub Blog.
]]>Organizations want AI tools that use RAG because it makes those tools aware of proprietary data without the effort and expense of custom model training. RAG also keeps models up to date. When generating an answer without RAG, models can only draw upon data that existed when they were trained. With RAG, on the other hand, models can leverage a private database of newer information for more informed responses.
We talked to GitHub Next’s Senior Director of Research, Idan Gazit, and Software Engineer, Colin Merkel, to learn more about RAG and how it’s used in generative AI tools.
Why everyone’s talking about RAG
One of the reasons you should always verify outputs from a generative AI tool is because its training data has a knowledge cut-off date. While models are able to produce outputs that are tailored to a request, they can only reference information that existed at the time of their training. But with RAG, an AI tool can use data sources beyond its model’s training data to generate an output.
The difference between RAG and fine-tuning
Most organizations currently don’t train their own AI models. Instead, they customize pre-trained models to their specific needs, often using RAG or fine-tuning. Here’s a quick breakdown of how these two strategies differ.
Fine-tuning requires adjusting a model’s weights, which results in a highly customized model that excels at a specific task. It’s a good option for organizations that rely on codebases written in a specialized language, especially if the language isn’t well-represented in the model’s original training data.
RAG, on the other hand, doesn’t require weight adjustment. Instead, it retrieves and gathers information from a variety of data sources to augment a prompt, which results in an AI model generating a more contextually relevant response for the end user.
Some organizations start with RAG and then fine-tune their models to accomplish a more specific task. Other organizations find that RAG is a sufficient method for AI customization alone.
How AI models use context
In order for an AI tool to generate helpful responses, it needs the right context. This is the same dilemma we face as humans when making a decision or solving a problem. It’s hard to do when you don’t have the right information to act on.
So, let’s talk more about context in the context ( ) of generative AI:
) of generative AI:
- Today’s generative AI applications are powered by large language models (LLMs) that are structured as transformers, and all transformer LLMs have a context window— the amount of data that they can accept in a single prompt. Though context windows are limited in size, they can and will continue to grow larger as more powerful models are released.
-
Input data will vary depending on the AI tool’s capabilities. For instance, when it comes to GitHub Copilot in the IDE, input data comprises all of the code in the file that you’re currently working on. This is made possible because of our Fill-in-the-Middle (FIM) paradigm, which makes GitHub Copilot aware of both the code before your cursor (the prefix) and after your cursor (the suffix).
GitHub Copilot also processes code from your other open tabs (a process we call neighboring tabs) to potentially find and add relevant information to the prompt. When there are a lot of open tabs, GitHub Copilot will scan the most recently reviewed ones.
-
Because of the context window’s limited size, the challenge of ML engineers is to figure out what input data to add to the prompt and in what order to generate the most relevant suggestion from the AI model. This task is known as prompt engineering.
How RAG enhances an AI model’s contextual understanding
With RAG, an LLM can go beyond training data and retrieve information from a variety of data sources, including customized ones.
When it comes to GitHub Copilot Chat within GitHub.com and in the IDE, input data can include your conversation with the chat assistant, whether it’s code or natural language, through a process called in-context learning. It can also include data from indexed repositories (public or private), a collection of Markdown documentation across repositories (that we refer to as knowledge bases), and results from integrated search engines. From these other sources, RAG will retrieve additional data to augment the initial prompt. As a result, it can generate a more relevant response.
The type of input data used by GitHub Copilot will depend on which GitHub Copilot plan you’re using.
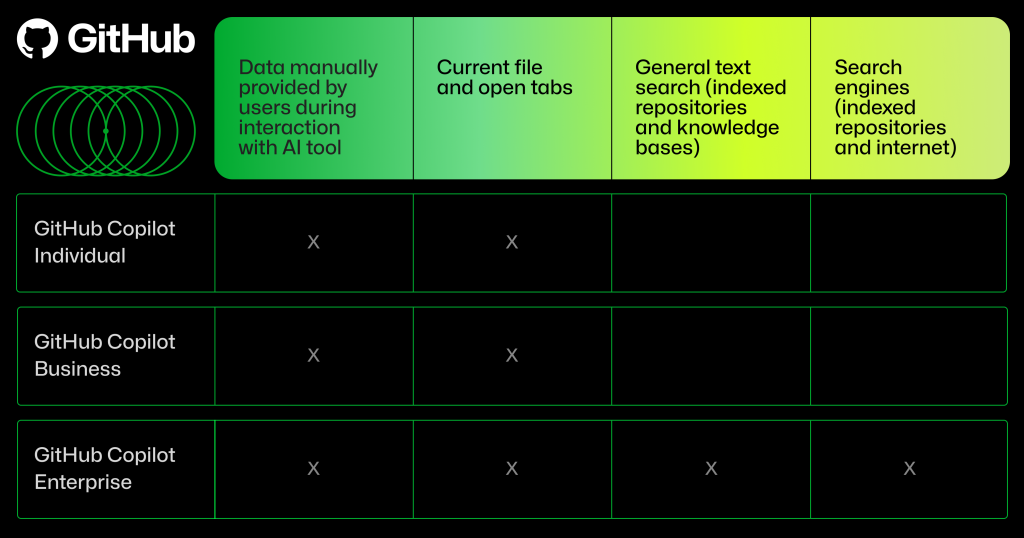
RAG and semantic search
Unlike keyword search or Boolean search operators, an ML-powered semantic search system uses its training data to understand the relationship between your keywords. So, rather than view, for example, “cats” and “kittens” as independent terms as you would in a keyword search, a semantic search system can understand, from its training, that those words are often associated with cute videos of the animal. Because of this, a search for just “cats and kittens” might rank a cute animal video as a top search result.
How does semantic search improve the quality of RAG retrievals? When using a customized database or search engine as a RAG data source, semantic search can improve the context added to the prompt and overall relevance of the AI-generated output.
The semantic search process is at the heart of retrieval. “It surfaces great examples that often elicit great results,” Gazit says.
Developers can use Copilot Chat on GitHub.com to ask questions and receive answers about a codebase in natural language, or surface relevant documentation and existing solutions.
RAG data sources: Where RAG uses semantic search
You’ve probably read dozens of articles (including some of our own) that talk about RAG, vector databases, and embeddings. And even if you haven’t, here’s something you should know: RAG doesn’t require embeddings or vector databases.
A RAG system can use semantic search to retrieve relevant documents, whether from an embedding-based retrieval system, traditional database, or search engine. The snippets from those documents are then formatted into the model’s prompt. We’ll provide a quick recap of vector databases and then, using GitHub Copilot Enterprise as an example, cover how RAG retrieves data from a variety of sources.
Vector databases
Vector databases are optimized for storing embeddings of your repository code and documentation. They allow us to use novel search parameters to find matches between similar vectors.
To retrieve data from a vector database, code and documentation are converted into embeddings, a type of high-dimensional vector, to make them searchable by a RAG system.
Here’s how RAG retrieves data from vector databases: while you code in your IDE, algorithms create embeddings for your code snippets, which are stored in a vector database. Then, an AI coding tool can search that database by embedding similarity to find snippets from across your codebase that are related to the code you’re currently writing and generate a coding suggestion. Those snippets are often highly relevant context, enabling an AI coding assistant to generate a more contextually relevant coding suggestion. GitHub Copilot Chat uses embedding similarity in the IDE and on GitHub.com, so it finds code and documentation snippets related to your query.
Embedding similarity is incredibly powerful because it identifies code that has subtle relationships to the code you’re editing.
“Embedding similarity might surface code that uses the same APIs, or code that performs a similar task to yours but that lives in another part of the codebase,” Gazit explains. “When those examples are added to a prompt, the model’s primed to produce responses that mimic the idioms and techniques that are native to your codebase—even though the model was not trained on your code.”
General text search and search engines
With a general text search, any documents that you want to be accessible to the AI model are indexed ahead of time and stored for later retrieval. For instance, RAG in GitHub Copilot Enterprise can retrieve data from files in an indexed repository and Markdown files across repositories.
RAG can also retrieve information from external and internal search engines. When integrated with an external search engine, RAG can search and retrieve information from the entire internet. When integrated with an internal search engine, it can also access information from within your organization, like an internal website or platform. Integrating both kinds of search engines supercharges RAG’s ability to provide relevant responses.
For instance, GitHub Copilot Enterprise integrates both Bing, an external search engine, and an internal search engine built by GitHub into Copilot Chat on GitHub.com. Bing integration allows GitHub Copilot Chat to conduct a web search and retrieve up-to-date information, like about the latest Java release. But without a search engine searching internally, ”Copilot Chat on GitHub.com cannot answer questions about your private codebase unless you provide a specific code reference yourself,” explains Merkel, who helped to build GitHub’s internal search engine from scratch.
Here’s how this works in practice. When a developer asks a question about a repository to GitHub Copilot Chat in GitHub.com, RAG in Copilot Enterprise uses the internal search engine to find relevant code or text from indexed files to answer that question. To do this, the internal search engine conducts a semantic search by analyzing the content of documents from the indexed repository, and then ranking those documents based on relevance. GitHub Copilot Chat then uses RAG, which also conducts a semantic search, to find and retrieve the most relevant snippets from the top-ranked documents. Those snippets are added to the prompt so GitHub Copilot Chat can generate a relevant response for the developer.
Key takeaways about RAG
RAG offers an effective way to customize AI models, helping to ensure outputs are up to date with organizational knowledge and best practices, and the latest information on the internet.
GitHub Copilot uses a variety of methods to improve the quality of input data and contextualize an initial prompt, and that ability is enhanced with RAG. What’s more, the RAG retrieval method in GitHub Copilot Enterprise goes beyond vector databases and includes data sources like general text search and search engine integrations, which provides even more cost-efficient retrievals.
Context is everything when it comes to getting the most out of an AI tool. To improve the relevance and quality of a generative AI output, you need to improve the relevance and quality of the input.
As Gazit says, “Quality in, quality out.”
Looking to bring the power of GitHub Copilot Enterprise to your organization? Learn more about GitHub Copilot Enterprise or get started now.
The post What is retrieval-augmented generation, and what does it do for generative AI? appeared first on The GitHub Blog.
]]>The post Customizing and fine-tuning LLMs: What you need to know appeared first on The GitHub Blog.
]]>How to write function in Python to reverse a string
How to write SQL query to select users from a database by age
How to implement binary search in Java
How often do you have to break the flow, leave your IDE, and search for answers to questions (that are maybe similar to the ones above)? And how often do you end up getting distracted and end up watching cat videos instead of getting back to work? (This happens to the best of them, even to GitHub’s VP of Developer Relations, Martin Woodward.)
It doesn’t have to be that way. A developer’s ability to get AI coding assistance directly in a workspace was found to reduce context switching and conserve a developer’s mental energy. When directly integrated into workspaces, these tools become familiar enough with a developer’s code to quickly provide tailored suggestions. Now, without getting sidetracked, developers can get customized answers to coding questions like:
Can you suggest a better way to structure my code for scalability?
Can you help me debug this function? It's not returning the expected results.
Can you help me understand this piece of code in this repository?
But how do AI coding assistants provide customized answers? What can organizations and developers do to receive more tailored solutions? And how, ultimately, do customized AI coding assistants benefit organizations as a whole?
We talked to Alireza Goudarzi, a senior machine learning researcher at GitHub, to get the answers. ⬇️
How AI coding assistants provide customized answers
When it comes to problem solving, context is everything.
Business decision makers use information gathered from internal metrics, customer meetings, employee feedback, and more to make decisions about what resources their companies need. Meanwhile, developers use details from pull requests, a folder in a project, open issues, and more to solve coding problems.
Large language models, or LLMs, do something similar:
- Generative AI coding tools are powered by LLMs, which are sets of algorithms trained on large amounts of code and human language.
- Today’s LLMs are structured as transformers, a kind of architecture that makes the model good at connecting the dots between data. Following the transformer architecture is what enables today’s LLMs to generate responses that are more contextually relevant than previous AI models.
- Though transformer LLMs are good at connecting the dots, they need to learn what data to process and in what order.
- A generative AI coding assistant in the IDE can be instructed to use data from open files or code written before and after the cursor to understand the context around the current line of code and suggest a relevant code completion.
- As a chatbot in an IDE or on a website, a generative AI coding assistant can provide guidance by using data from indexed repositories, customized knowledge bases, developer-provided input in a prompt or query, and even search engine integrations.
All input data—the code, query, and additional context—passes through something called a context window, which is present in all transformer-based LLMs. The size of the context window represents the capacity of data an LLM can process. Though it can’t process an infinite amount of data, it can grow larger. But because that window is limited, prompt engineers have to figure out what data, and in what order, to feed the model so it generates the most useful, contextually relevant responses for the developer.
How to customize your LLM
Customizing an LLM is not the same as training it. Training an LLM means building the scaffolding and neural networks to enable deep learning. Customizing an LLM means adapting a pre-trained LLM to specific tasks, such as generating information about a specific repository or updating your organization’s legacy code into a different language.
There are a few approaches to customizing your LLM: retrieval augmented generation, in-context learning, and fine-tuning.
We broke these down in this post about the architecture of today’s LLM applications and how GitHub Copilot is getting better at understanding your code. Here’s a recap.
Retrieval-augmented generation (RAG)
RAG typically uses something called embeddings to retrieve information from a vector database. Vector databases are a big deal because they transform your source code into retrievable data while maintaining the code’s semantic complexity and nuance.
In practice, that means an LLM-based coding assistant using RAG can generate relevant answers to questions about a private repository or proprietary source code. It also means that LLMs can use information from external search engines to generate their responses.
If you’re wondering what a vector database is, we have you covered:
- Vector databases store embeddings of your repository code and documentation. The embeddings are what make your code and documentation readable by an LLM. (This is similar to the way programming languages are converted into a binary system language for a computer to understand.)
- As developers code in an IDE, algorithms transform code snippets in the IDE into embeddings. Algorithms then make approximate matches between the embeddings that are created for those IDE snippets and the embeddings already stored in the vector database.
- When asking a question to a chat-based AI coding assistant, the questions and requests written in natural language are also transformed into embeddings. A similar process to the one described above takes place: the embeddings created for the natural language prompts are matched to embeddings already stored in vector databases.
Vector databases and embeddings allow algorithms to quickly search for approximate matches (not just exact ones) on the data they store. This is important because if an LLM’s algorithms only make exact matches, it could be the case that no data is included as context. Embeddings improve an LLM’s semantic understanding, so the LLM can find data that might be relevant to a developer’s code or question and use it as context to generate a useful response.
|
Have questions about what data GitHub Copilot uses and how?
Read this for answers to frequently asked questions and visit the GitHub Copilot Trust Center for more details. |
In-context learning
In-context learning, a method sometimes referred to as prompt engineering, is when developers give the model specific instructions or examples at the time of inference (also known as the time they’re typing or vocalizing a question or request). By providing these instructions and examples, the LLM understands the developer is asking it to infer what they need and will generate a contextually relevant output.
In-context learning can be done in a variety of ways, like providing examples, rephrasing your queries, and adding a sentence that states your goal at a high-level.
Fine-tuning
Fine-tuning your model can result in a highly customized LLM that excels at a specific task. There are two ways to customize your model with fine-tuning: supervised learning and reinforcement learning from human feedback (RLHF).
Under supervised learning, there is a predefined correct answer that the model is taught to generate. Under RLHF, there is high-level feedback that the model uses to gauge whether its generated response is acceptable or not.
Let’s dive deeper.
Supervised learning
This method is when the model’s generated output is evaluated against an intended or known output. For example, you know that the sentiment behind a statement like this is negative: “This sentence is unclear.” To evaluate the LLM, you’d feed this sentence to the model and query it to label the sentiment as positive or negative.
If the model labels it as positive, then you’d adjust the model’s parameters (variables that can be weighed or prioritized differently to change a model’s output) and try prompting it again to see if it can classify the sentiment as negative.
But even smaller models can have over 300 million parameters. Those are a lot of variables to sift through and adjust (and re-adjust). This method also requires time-intensive labeling. Each input sample requires an output that’s labeled with exactly the correct answer, such as “Negative,” for the example above. That label gives the output something to measure against so adjustments can be made to the model’s parameters.
Reinforcement learning from human feedback (RLHF)
RLHF requires either direct human feedback or creating a reward model that’s trained to model human feedback (by predicting if a user will accept or reject the output from the pre-trained LLM). The learnings from the reward model are passed to the pre-trained LLM, which will adjust its outputs based on user acceptance rate.
The benefit to RLHF is that it doesn’t require supervised learning and, consequently, expands the criteria for what’s an acceptable output. For example, with enough human feedback, the LLM can learn that if there’s an 80% probability that a user will accept an output, then it’s fine to generate.
For more on LLMs and how they process data, read:
- The architecture of today’s LLM applications
- How LLMs can do things they weren’t trained to do
- How generative AI is changing the way developers work
- How GitHub Copilot is getting better at understanding your code
- What developers need to know about generative AI
- A developer’s guide to prompt engineering and LLMs
How to customize GitHub Copilot
GitHub Copilot’s contextual understanding has continuously evolved over time. The first version was only able to consider the file you were working on in your IDE to be contextually relevant. We then expanded the context to neighboring tabs, which are all the open files in your IDE that GitHub Copilot can comb through to find additional context.
Just a year and a half later, we launched GitHub Copilot Enterprise, which uses an organization’s indexed repositories to provide developers with coding assistance that’s customized to their codebases. With GitHub Copilot Enterprise, organizations can tailor GitHub Copilot suggestions in the following ways:
- Index their source code repositories in vector databases, which improves semantic search and gives their developers a customized coding experience.
-
Create knowledge bases, which are Markdown files from a collection of repositories that provide GitHub Copilot with additional context through unstructured data, or data that doesn’t live in a database or spreadsheet.
In practice, this can benefit organizations in several ways:
- Enterprise developers gain a deeper understanding of your organization’s unique codebase. Senior and junior developers alike can prompt GitHub Copilot for code summaries, coding suggestions, and answers about code behavior. As a result of this streamlined code navigation and comprehension, enterprise developers implement features, resolve issues, and modernize code faster.
- Complex data is quickly translated into organizational knowledge and best practices. Because GitHub Copilot receives context through the repositories and documentation your organization chooses to index, developers receive coding suggestions and guidance that are more useful because they align with organizational knowledge and best practices.
It’s not just developers, but also their non-developer and cross-functional team members who can use natural language to prompt Copilot Chat in GitHub.com for answers and guidance on relevant documentation or existing solutions. Data and solutions captured in repositories becomes more accessible across the organization, improving collaboration and increasing awareness of business goals and practices. - Faster pull requests create smart, efficient, and accessible development workflows. With GitHub Copilot Enterprise, developers can use GitHub Copilot to generate pull request summaries directly in GitHub.com, helping them communicate clearly with reviewers while also saving valuable time. For developers reviewing pull requests, GitHub Copilot can be used to help them quickly gain a strong understanding of proposed changes and, as a result, focus more time on providing valuable feedback.
|
GitHub Copilot Enterprise is now generally available.
Read more about GitHub’s most advanced AI offering, and how it’s customized to your organization’s knowledge and codebase. |
Best practices for customizing your LLM
Customized LLMs help organizations increase value out of all of the data they have access to, even if that data’s unstructured. Using this data to customize an LLM can reveal valuable insights, help you make data-driven decisions, and make enterprise information easier to find overall.
Here are our top tips for customizing an LLM.
Select an AI solution that uses RAG
Like we mentioned above, not all of your organization’s data will be contained in a database or spreadsheet. A lot of data comes in the form of text, like code documentation.
Organizations that opt into GitHub Copilot Enterprise will have a customized chat experience with GitHub Copilot in GitHub.com. GitHub Copilot Chat will have access to the organization’s selected repositories and knowledge base files (also known as Markdown documentation files) across a collection of those repositories.
Adopt innersource practices
Kyle Daigle, GitHub’s chief operating officer, previously shared the value of adapting communication best practices from the open source community to their internal teams in a process known as innersource. One of those best practices is writing something down and making it easily discoverable.
How does this practice pay off? It provides more documentation, which means more context for an AI tool to generate tailored solutions to our organization. Effective AI adoption requires establishing this foundation of context.
Moreover, developers can use GitHub Copilot Chat in their preferred natural language—from German to Telugu. That means more documentation, and therefore more context for AI, improves global collaboration. All of your developers can work on the same code while using their own natural language to understand and improve it.
Here are Daigle’s top tips for innersource adoption:
- If you like what you hear, record it and make it discoverable (and remember: plenty of video and productivity tools now provide AI-powered summaries and action items).
- If you come up with a useful solution for your team, share it out with the wider organization so they can benefit from it, too.
- Offer feedback to publicly shared information and solutions. But remember to critique the work, not the person.
- If you request a change to a project or document, explain why you’re requesting that change.
✨ Bonus points if you add all of these notes to your relevant GitHub repositories and format them in Markdown.
How do you expand your LLM results?
The answer lies in search engine integration.
Transformer-based LLMs have impressive semantic understanding even without embedding and high-dimensional vectors. This is because they’re trained on a large_ _amount of unlabeled natural language data and publicly available source code. They also use a self-supervised learning process where they use a portion of input data to learn basic learning objectives, and then apply what they’ve learned to the rest of the input.
When a search engine is integrated into an LLM application, the LLM is able to retrieve search engine results relevant to your prompt because of the semantic understanding it’s gained through its training. That means an LLM-based coding assistant with search engine integration (made possible through a search engine’s API) will have a broader pool of current information that it can retrieve information from.
Why does this matter to your organization?
Let’s say a developer asks an AI coding tool a question about the most recent version of Java. However, the LLM was trained on data from before the release, and the organization hasn’t updated its repositories’ knowledge with information about the latest release. The AI coding tool can still answer the developer’s question by conducting a web search to retrieve the answer.
A generative AI coding assistant that can retrieve data from both custom and publicly available data sources gives employees customized and comprehensive guidance.
The path forward
50% of enterprise software engineers are expected to use machine-learning powered coding tools by 2027, according to Gartner.
Today, developers are using AI coding assistants to get a head start on complex code translation tasks, build better test coverage, tackle new problems with creative solutions, and find answers to coding-related questions without leaving their IDEs. With customization, developers can also quickly find solutions tailored to an organization’s proprietary or private source code, and build better communication and collaboration with their non-technical team members.
In the future, we imagine a workspace that offers more customization for organizations. For example, your ability to fine-tune a generative AI coding assistant could improve code completion suggestions. Additionally, integrating an AI coding tool into your custom tech stack could feed the tool with more context that’s specific to your organization and from services and data beyond GitHub.
The post Customizing and fine-tuning LLMs: What you need to know appeared first on The GitHub Blog.
]]>The post The architecture of SAST tools: An explainer for developers appeared first on The GitHub Blog.
]]>In today’s age of shifting left—an approach to coding that integrates security checks earlier into the software development lifecycle (SDLC)—developers are expected to be proficient at using security tools. This additional responsibility can be overwhelming for developers who don’t specialize in security. The main issue: on top of their normal responsibilities, developers have to sift through many false positive alerts to find and address the real, critical vulnerabilities.
But shifting left isn’t going anywhere. Its benefits have been proven. So, what can developers do to improve their security experience? They can start by understanding how different security tooling works, the latest advancements, and why they matter. By understanding the inner workings of a static application security testing (SAST) tool, developers can better interpret its results and fix vulnerable code, feel empowered to contribute to security discussions and decisions, and improve their relationship with security teams.
In this post, we’ll cover what our security experts, Sylwia Budzynska, Keith Hoodlet, and Nick Liffen, have written about SAST tools—from what they are and how they work—and break down why they’re important to developers who are coding in the age of security-first development.
Why developers and security experts use SAST tools
GitHub Security Researcher Sylwia Budzynska wrote a post about common uses of SAST tools. Here’s a quick recap.
Developers and security experts rely on SAST tools to:
- Automate source code scanning to prevent vulnerabilities and catch them earlier in the development pipeline.
-
Expand vulnerability detection. Through a technique called variant analysis, SAST tools can find new vulnerabilities by detecting variants of a known vulnerability in different parts of the code base.
-
Assist with manual code reviews. In CodeQL, GitHub’s SAST tool, your code is treated and analyzed as data. This allows you to execute queries against the database to retrieve the data you want from your code, like patterns that highlight potential vulnerabilities. You can run standard CodeQL queries written by GitHub researchers and community contributors, or write your own to conduct a custom analysis.
GitHub’s security team used a combination of AI-generated models and variant analysis to discover a new vulnerability. Here’s how.
For comprehensive coverage, organizations often use SAST in tandem with other security testing, including:
- Software composition analysis (SCA), which identifies vulnerabilities in a codebase that stem from a third-party dependency. An SCA tool like Dependabot scans the origins of the third-party code for security threats and licensing requirements. With this information, you can update your codebase by addressing vulnerabilities, attributing credit, or complying with the open source license accordingly. SCA tools can be used at any point in the SDLC. \
- Dynamic application security testing (DAST) finds security vulnerabilities in an application once it’s running.
- Interactive application security testing (IAST) combines SAST and DAST to identify vulnerabilities that might be missed by either one alone.
The pros and cons of SAST
Let’s start with the pros:
- Modern SAST tools can be used early in the SDLC. Ideally, this means that builds and production shouldn’t be disrupted by vulnerable code.
- Given that organizations typically have one security expert for every 100 developers, vulnerabilities are bound to be overlooked when code reviews are only done manually. SAST tools are designed and known for their ability to analyze the entire codebase, which can augment manual code reviews. This helps teams detect challenging vulnerabilities and improves the speed at which they ship secure and quality code.
- SAST tools are valued for their ability to trace data flows. This allows them to identify where in the source code sensitive data might leak, check that all data inputs are validated and sanitized, and verify that security protocols are followed when data is stored or transferred.
- While most SAST tools only trace partial data flows, CodeQL uses a database to represent your source code, so it has a full understanding of how data flows throughout your whole application.
- Advanced SAST tools can integrate directly in your build process, or CI/CD pipeline, while having access to your codebase. That means your code is automatically scanned for vulnerabilities with every push or build.
- SAST tools like CodeQL make it easy for developers to address vulnerabilities by providing security alerts that state the exact line of code that triggered the alert, the nature of the alert, properties of the alert (like its severity level), and how to fix the problem.
- Coupling SAST tooling with generative AI speeds up this process by suggesting an AI-generated code fix to developers. For instance, developers who use Github Advanced Security’s code scanning autofix feature can apply AI-generated code fixes to easily remediate vulnerabilities directly in a pull request.
Now, some cons. Well, mainly the big one: false positives.
| Problems and consequences | Solutions |
| Your SAST tool might match vulnerable patterns in a database to patterns found in comments throughout the source code and in harmless function names. | Adding a lexical analysis function–which transforms code into tokens and ignores characters that aren’t related to the semantics of code—filters out pattern matches unrelated to the source code (like patterns found in your code comments). |
| A legacy SAST tool might not be able to differentiate between input data that comes from a user (and therefore exploitable) and input data that comes from a local source (and therefore benign).
Your SAST tool might not detect when input data has been sanitized or validated as it moves throughout your source code (making the data safe). |
Abstracting your code into a hierarchical structure provides a better understanding of where input data enters and is used throughout your code. As a result, the SAST tool will better determine when input data is actually exploitable and raises fewer false positives. |
| With so many false positives, developers and security experts may lose confidence in the tool’s data and get alert fatigue, which can cause them to skim past critical alerts. | A SAST tool with an alert system that can be set with custom and automated triage rules ensures that the most urgent security alerts are addressed first. Engineering teams should also be able to filter and search alerts to sift through all the results and focus on a particular type of alert. |
For further reading on false positives, read:
- 5 ways to make your DevSecOps strategy developer-friendly
- The fundamentals of static analysis and vulnerability research
- The 3 types of static analysis
How do SAST tools work?
SQL injections—malicious SQL code that allows users to gain access to sensitive data—are a common vulnerability that is easier to find with SAST than with other testing methods. This is because SAST tools trace data flows, and SQL injections target applications that store and retrieve data in SQL databases.

Methods used by SAST tools to find vulnerabilities include:
- Signature-based pattern matching matches patterns of known injection techniques to patterns found in your source code.
- Semantic analysis not only matches patterns, but also considers how your code was constructed—the surrounding context, logic, and dependencies between different code parts—when scanning for vulnerabilities.
- Taint analysis tracks the flow of input data throughout your source code to see if it ends up in a function that could be exploited with malicious user input.
🕵🏻♀️ Let’s focus on semantic and taint analysis, which provide more flexibility, precision, and broader coverage than signature-based matching (or other legacy methods of static analysis).
We’ll break down how an advanced SAST tool like CodeQL uses semantic and taint analysis to trace a full data flow and find vulnerabilities in your code. 👇
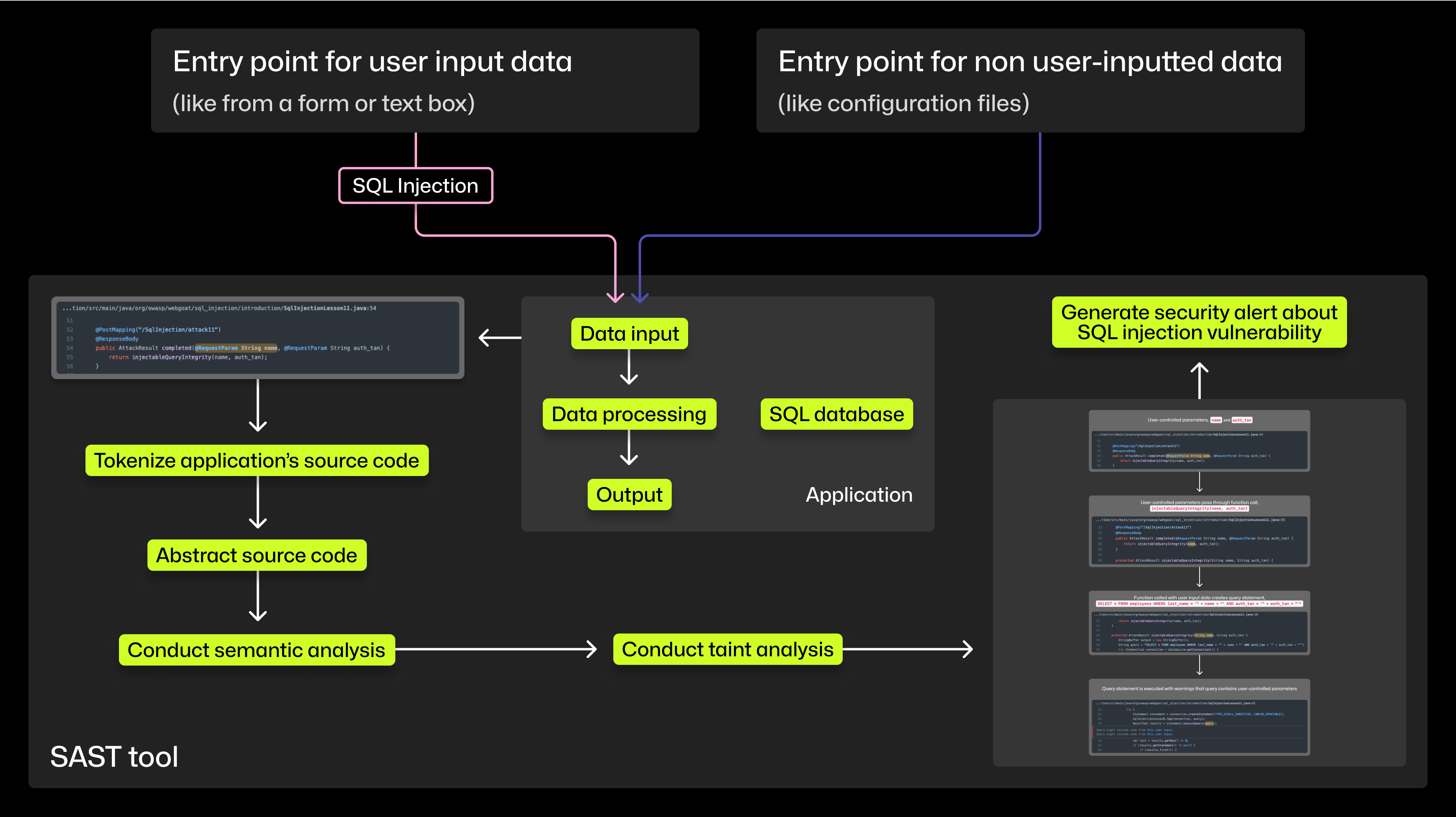
Here’s code that contains a user-controlled parameter, or a parameter where the user submits data:
@postmapping("/sqlinjection/attack11")
@responsebody
public Attackresult completed(@requestparam string name, @requestparam String auth_tan) {
return injectablequeryintegrity(name, auth_tan);
}
1. Tokenize the source code
SAST tools use lexical analysis to transform code into tokens. Because tokens are categorized according to the grammar rules of a programming language, your code becomes a list of standardized parts that makes it easier to analyze. Tokenizing source code allows the SAST tool to conduct a semantic analysis that ignores characters unrelated to the semantics of your code.
2. Abstract the source code
To help decipher the meaning of source code and its structure, most SAST tools visualize your source code as a tree. An abstract syntax tree (AST) transforms lines of your code into a hierarchical structure to show relationships between code, which code belongs with which function, and more.
Here’s what an AST looks like and here’s how to view the AST of your source code.
3. Conduct semantic analysis
Aided by an abstraction of the source code, this analysis allows the SAST tool to understand the code’s meaning and structure. As we mentioned above, a semantic analysis enables CodeQL to ignore tokens that aren’t related to the semantics of your source code. As a result, the SAST tool scans your source code (and not your code comments) for vulnerabilities.
4. Conduct a taint analysis
Earlier, we noted that SQL injections enter your source code through unsanitized or invalidated user input data. But SAST tools look for vulnerabilities in the way your source code handles data, not the data itself. In other words, SAST tools scan the source code written by a developer, not input data entered by a user. This is where taint analysis comes in.
A SAST tool uses taint analysis to do three things:
- Identify sources, sanitizers, and sinks. Sources are where the input data enters the source code, sanitizers are functions that make input safe, and sinks are functions that if called with unsanitized data could cause harm.
- Track the flow of input data from a source to a sink. The taint analysis uses abstractions from your source code to follow input data from a source to see if it ends up in a sink or a function that could be exploited with that user input data.
- Check if input data—whether it’s from the user or a local, benign source— passes through sanitization or validation functions as the input data flows from source to sink.
Advanced SAST tools like CodeQL can evaluate how well these functions actually sanitize or validate the data, and use that judgment to decide whether or not to raise the path as a potential vulnerability. If any input data doesn’t pass through these sanitizing functions, the tool will flag the path as a potential vulnerability.

Above is an example of how CodeQL traces data flow. The two statements in the last step, Query might include code from this user input is evidence of the CodeQL data flow at work.
The SAST tools recognizes that user-provided data, name and auth_tan, are directly embedded into the SQL query, SELECT * FROM employees WHERE last_name = ‘“ + name + “‘ AND auth_tan = ‘“ + auth_tan + “‘“.
Executing this query might generate a security alert if the user input hasn’t passed through sufficient sanitizers or any sanitizers at all.
📝 Two important notes:
- Finding a sink is not the same as finding a vulnerability. A sink or a sensitive function on its own isn’t a vulnerability, and many sinks can be used safely. Locating a sink means the tool has found a _potentially _vulnerable source of code in that it’s a function that _could _be exploited if unsanitized input data calls that function.
- For a vulnerability to exist, the tool must find that unsanitized or invalidated input data can flow from source to sink without going through a sanitizer. To determine if a sink is a vulnerability, the SAST tool must use taint analysis to trace the possible paths that the unsanitized or invalidated input data can take to sensitive functions. (That’s where abstractions of your source code come in handy.) If a SAST tool finds such a data flow, it’ll send an alert about a potential security vulnerability to engineering teams.
🔒 At the end of these four processes, engineering teams will receive security alerts from the SAST tool. To ensure teams address the most urgent security alerts first, it’s important to set custom and automated triage rules and have the ability to filter and search alerts to focus on a particular type.
5. Run custom queries
Another way that some SAST tools can find vulnerabilities is when developers and security experts write queries to search for certain vulnerabilities. CodeQL, in particular, is known for its flexibility in that it allows developers to write custom queries that meet the needs of their codebase.
You can run standard CodeQL queries or write your own to conduct a custom analysis.
Learn how to practice writing your own CodeQL query with these resources:
- Query language tutorials can teach you how to write queries and introduce you to key logic concepts.
- CodeQL query basics provides fundamental knowledge about CodeQL queries and how to troubleshoot.
- Writing your own CodeQL query provides step-by-step instructions (as well as exercises) for writing and refining your CodeQL queries.
Automating SAST
Instead of manually pushing a code scan, developers can integrate a modern SAST tool into their current CI/CD pipeline, automating vulnerability code scans with every push or build.
A SAST tool that’s integrated into your build process while having access to your codebase means the tool can better understand the semantic elements of your code and conduct a more comprehensive taint analysis, according to Keith Hoodlet, principal security specialist at GitHub.
Why we need SAST
When you create or work with an application, you need to make sure that it handles data securely. For instance, an educational project designed to be used by students might be subject to the Children’s Online Privacy Protection Act (COPPA), which requires websites that gather data from children under 13 report any breaches to parents.
Wordplay, an educational programming language and web-based IDE is designed to be used by students, which means most project contributors are aspiring developers who are just starting to learn best practices of secure code writing. Consequently, the project needs to protect against data breaches that could expose the projects and identity of those students.
“When students submit pull requests that touch any private data, they need to know that they aren’t shipping common vulnerability patterns that might leak it,” says Amy Ko, founder.
But limited bandwidth makes it difficult to review every single line of submitted code. That’s why the Wordplay team relies on CodeQL to integrate vulnerability checks into its CI/CD pipeline.
“CodeQL is like having a community of experienced security developers regularly code reviewing our work,” Ko adds. “The key reason we use it is to expand our team’s expertise and capacity.”
In addition to using CodeQL to prevent data breaches, the Wordplay team has ideas about how it might use the tool to find patterns that could lead to accessibility issues, like lack of feedback in response to keyboard inputs. For example, CodeQL could be used to identify input sequences that don’t provide feedback.
How SAST helps developers in a new age of coding
Modern SAST tools help developers adapt to this new age of coding. As they take on additional security responsibilities in the shift left movement, developers can rely on SAST tools to trace data flows and locations of exploitable vulnerabilities throughout their projects. What’s more: as developers write more code with the help of AI coding assistants, they can feel more confident that SAST is analyzing their entire source code for vulnerabilities.
Getting to know the workings of a SAST tool, which is one of the most widely used security tools, will give developers a better understanding of its results and security alerts, and that can empower them to actively participate in security discussions and decisions—ultimately benefiting engineering and security teams alike, and organizations overall.
Harness the power of CodeQL. Learn more or get started now.
The post The architecture of SAST tools: An explainer for developers appeared first on The GitHub Blog.
]]>The post The architecture of today’s LLM applications appeared first on The GitHub Blog.
]]>In this post, we’ll cover five major steps to building your own LLM app, the emerging architecture of today’s LLM apps, and problem areas that you can start exploring today.
Five steps to building an LLM app
Building software with LLMs, or any machine learning (ML) model, is fundamentally different from building software without them. For one, rather than compiling source code into binary to run a series of commands, developers need to navigate datasets, embeddings, and parameter weights to generate consistent and accurate outputs. After all, LLM outputs are probabilistic and don’t produce the same predictable outcomes.

Let’s break down, at a high level, the steps to build an LLM app today.
1. Focus on a single problem, first. The key? Find a problem that’s the right size: one that’s focused enough so you can quickly iterate and make progress, but also big enough so that the right solution will wow users.
For instance, rather than trying to address all developer problems with AI, the GitHub Copilot team initially focused on one part of the software development lifecycle: coding functions in the IDE.
2. Choose the right LLM. You’re saving costs by building an LLM app with a pre-trained model, but how do you pick the right one? Here are some factors to consider:
- Licensing. If you hope to eventually sell your LLM app, you’ll need to use a model that has an API licensed for commercial use. To get you started on your search, here’s a community-sourced list of open LLMs that are licensed for commercial use.
- Model size. The size of LLMs can range from 7 to 175 billion parameters—and some, like Ada, are even as small as 350 million parameters. Most LLMs (at the time of writing this post) range in size from 7-13 billion parameters.
Conventional wisdom tells us that if a model has more parameters (variables that can be adjusted to improve a model’s output), the better the model is at learning new information and providing predictions. However, the improved performance of smaller models is challenging that belief. Smaller models are also usually faster and cheaper, so improvements to the quality of their predictions make them a viable contender compared to big-name models that might be out of scope for many apps.
- Model performance. Before you customize your LLM using techniques like fine-tuning and in-context learning (which we’ll cover below), evaluate how well and fast—and how consistently—the model generates your desired output. To measure model performance, you can use offline evaluations.
3. Customize the LLM. When you train an LLM, you’re building the scaffolding and neural networks to enable deep learning. When you customize a pre-trained LLM, you’re adapting the LLM to specific tasks, such as generating text around a specific topic or in a particular style. The section below will focus on techniques for the latter. To customize a pre-trained LLM to your specific needs, you can try in-context learning, reinforcement learning from human feedback (RLHF), or fine-tuning.
- In-context learning, sometimes referred to as prompt engineering by end users, is when you provide the model with specific instructions or examples at the time of inference—or the time you’re querying the model—and asking it to infer what you need and generate a contextually relevant output.
In-context learning can be done in a variety of ways, like providing examples, rephrasing your queries, and adding a sentence that states your goal at a high-level.
- RLHF comprises a reward model for the pre-trained LLM. The reward model is trained to predict if a user will accept or reject the output from the pre-trained LLM. The learnings from the reward model are passed to the pre-trained LLM, which will adjust its outputs based on user acceptance rate.
The benefit to RLHF is that it doesn’t require supervised learning and, consequently, expands the criteria for what’s an acceptable output. With enough human feedback, the LLM can learn that if there’s an 80% probability that a user will accept an output, then it’s fine to generate. Want to try it out? Check out these resources, including codebases, for RLHF.
- Fine-tuning is when the model’s generated output is evaluated against an intended or known output. For example, you know that the sentiment behind a statement like this is negative: “The soup is too salty.” To evaluate the LLM, you’d feed this sentence to the model and query it to label the sentiment as positive or negative. If the model labels it as positive, then you’d adjust the model’s parameters and try prompting it again to see if it can classify the sentiment as negative.
Fine-tuning can result in a highly customized LLM that excels at a specific task, but it uses supervised learning, which requires time-intensive labeling. In other words, each input sample requires an output that’s labeled with exactly the correct answer. That way, the actual output can be measured against the labeled one and adjustments can be made to the model’s parameters. The advantage of RLHF, as mentioned above, is that you don’t need an exact label.
4. Set up the app’s architecture. The different components you’ll need to set up your LLM app can be roughly grouped into three categories:
- User input which requires a UI, an LLM, and an app hosting platform.
- Input enrichment and prompt construction tools. This includes your data source, embedding model, a vector database, prompt construction and optimization tools, and a data filter.
-
Efficient and responsible AI tooling, which includes an LLM cache, LLM content classifier or filter, and a telemetry service to evaluate the output of your LLM app.
5. Conduct online evaluations of your app. These evaluations are considered “online” because they assess the LLM’s performance during user interaction. For example, online evaluations for GitHub Copilot are measured through acceptance rate (how often a developer accepts a completion shown to them), as well as the retention rate (how often and to what extent a developer edits an accepted completion).
The emerging architecture of LLM apps
Let’s get started on architecture. We’re going to revisit our friend Dave, whose Wi-Fi went out on the day of his World Cup watch party. Fortunately, Dave was able to get his Wi-Fi running in time for the game, thanks to an LLM-powered assistant.
We’ll use this example and the diagram above to walk through a user flow with an LLM app, and break down the kinds of tools you’d need to build it.

User input tools
When Dave’s Wi-Fi crashes, he calls his internet service provider (ISP) and is directed to an LLM-powered assistant. The assistant asks Dave to explain his emergency, and Dave responds, “My TV was connected to my Wi-Fi, but I bumped the counter, and the Wi-Fi box fell off! Now, we can’t watch the game.”
In order for Dave to interact with the LLM, we need four tools:
- LLM API and host: Is the LLM app running on a local machine or in the cloud? In an ISP’s case, it’s probably hosted in the cloud to handle the volume of calls like Dave’s. Vercel and early projects like jina-ai/rungpt aim to provide a cloud-native solution to deploy and scale LLM apps.
But if you want to build an LLM app to tinker, hosting the model on your machine might be more cost effective so that you’re not paying to spin up your cloud environment every time you want to experiment. You can find conversations on GitHub Discussions about hardware requirements for models like LLaMA‚ two of which can be found here and here.
- The UI: Dave’s keypad is essentially the UI, but in order for Dave to use his keypad to switch from the menu of options to the emergency line, the UI needs to include a router tool.
- Speech-to-text translation tool: Dave’s verbal query then needs to be fed through a speech-to-text translation tool that works in the background.
Input enrichment and prompt construction tools
Let’s go back to Dave. The LLM can analyze the sequence of words in Dave’s transcript, classify it as an IT complaint, and provide a contextually relevant response. (The LLM’s able to do this because it’s been trained on the internet’s entire corpus, which includes IT support documentation.)
Input enrichment tools aim to contextualize and package the user’s query in a way that will generate the most useful response from the LLM.
- A vector database is where you can store embeddings, or index high-dimensional vectors. It also increases the probability that the LLM’s response is helpful by providing additional information to further contextualize your user’s query.
Let’s say the LLM assistant has access to the company’s complaints search engine, and those complaints and solutions are stored as embeddings in a vector database. Now, the LLM assistant uses information not only from the internet’s IT support documentation, but also from documentation specific to customer problems with the ISP.
- But in order to retrieve information from the vector database that’s relevant to a user’s query, we need an embedding model to translate the query into an embedding. Because the embeddings in the vector database, as well as Dave’s query, are translated into high-dimensional vectors, the vectors will capture both the semantics and intention of the natural language, not just its syntax.
Here’s a list of open source text embedding models. OpenAI and Hugging Face also provide embedding models.
Dave’s contextualized query would then read like this:
// pay attention to the the following relevant information.
to the colors and blinking pattern.
// pay attention to the following relevant information.
// The following is an IT complaint from, Dave Anderson, IT support expert.
Answers to Dave's questions should serve as an example of the excellent support
provided by the ISP to its customers.
*Dave: Oh it's awful! This is the big game day. My TV was connected to my
Wi-Fi, but I bumped the counter and the Wi-Fi box fell off and broke! Now we
can't watch the game.
Not only do these series of prompts contextualize Dave’s issue as an IT complaint, they also pull in context from the company’s complaints search engine. That context includes common internet connectivity issues and solutions.
MongoDB released a public preview of Vector Atlas Search, which indexes high-dimensional vectors within MongoDB. Qdrant, Pinecone, and Milvus also provide free or open source vector databases.
- A data filter will ensure that the LLM isn’t processing unauthorized data, like personal identifiable information. Preliminary projects like amoffat/HeimdaLLM are working to ensure LLMs access only authorized data.
- A prompt optimization tool will then help to package the end user’s query with all this context. In other words, the tool will help to prioritize which context embeddings are most relevant, and in which order those embeddings should be organized in order for the LLM to produce the most contextually relevant response. This step is what ML researchers call prompt engineering, where a series of algorithms create a prompt. (A note that this is different from the prompt engineering that end users do, which is also known as in-context learning).
Prompt optimization tools like langchain-ai/langchain help you to compile prompts for your end users. Otherwise, you’ll need to DIY a series of algorithms that retrieve embeddings from the vector database, grab snippets of the relevant context, and order them. If you go this latter route, you could use GitHub Copilot Chat or ChatGPT to assist you.
| Learn how the GitHub Copilot team uses the Jaccard similarity to decide which pieces of context are most relevant to a user’s query > |
Efficient and responsible AI tooling
To ensure that Dave doesn’t become even more frustrated by waiting for the LLM assistant to generate a response, the LLM can quickly retrieve an output from a cache. And in the case that Dave does have an outburst, we can use a content classifier to make sure the LLM app doesn’t respond in kind. The telemetry service will also evaluate Dave’s interaction with the UI so that you, the developer, can improve the user experience based on Dave’s behavior.
- An LLM cache stores outputs. This means instead of generating new responses to the same query (because Dave isn’t the first person whose internet has gone down), the LLM can retrieve outputs from the cache that have been used for similar queries. Caching outputs can reduce latency, computational costs, and variability in suggestions.
You can experiment with a tool like zilliztech/GPTcache to cache your app’s responses.
- A content classifier or filter can prevent your automated assistant from responding with harmful or offensive suggestions (in the case that your end users take their frustration out on your LLM app).
Tools like derwiki/llm-prompt-injection-filtering and laiyer-ai/llm-guard are in their early stages but working toward preventing this problem.
- A telemetry service will allow you to evaluate how well your app is working with actual users. A service that responsibly and transparently monitors user activity (like how often they accept or change a suggestion) can share useful data to help improve your app and make it more useful.
OpenTelemetry, for example, is an open source framework that gives developers a standardized way to collect, process, and export telemetry data across development, testing, staging, and production environments.
Learn how GitHub uses OpenTelemetry to measure Git performance >
Woohoo!  Your LLM assistant has effectively answered Dave’s many queries. His router is up and working, and he’s ready for his World Cup watch party. Mission accomplished!
Your LLM assistant has effectively answered Dave’s many queries. His router is up and working, and he’s ready for his World Cup watch party. Mission accomplished!
Real-world impact of LLMs
Looking for inspiration or a problem space to start exploring? Here’s a list of ongoing projects where LLM apps and models are making real-world impact.
- NASA and IBM recently open sourced the largest geospatial AI model to increase access to NASA earth science data. The hope is to accelerate discovery and understanding of climate effects.
- Read how the Johns Hopkins Applied Physics Laboratory is designing a conversational AI agent that provides, in plain English, medical guidance to untrained soldiers in the field based on established care procedures.
- Companies like Duolingo and Mercado Libre are using GitHub Copilot to help more people learn another language (for free) and democratize ecommerce in Latin America, respectively.
Further reading
- A developer’s guide to open source LLMs and generative AI
- Demystifying LLMs: How they can do things they weren’t trained to do
- A developer’s guide to prompt engineering and LLMs
- How to build an enterprise LLM application: Lessons from GitHub Copilot
The post The architecture of today’s LLM applications appeared first on The GitHub Blog.
]]>The post A guide to designing and shipping AI developer tools appeared first on The GitHub Blog.
]]>While it can now feel like there’s a new AI announcement from every company every week, we’re here to reflect on what it takes to build an AI product from scratch—not just to integrate an LLM into an existing product. In this article, we’ll share 10 tips for designing AI products and developer tools, and lessons we learned first-hand from designing, iterating, and extending GitHub Copilot.

Let’s jump in.
Tip 1: Build on the creative power of natural language
“The hottest new design system is natural language,” reports the team designing GitHub Copilot. According to them, the most important tools to develop right now are ones that will allow people to describe, in their respective natural languages, what they want to create, and then get the output that they want.
Leveraging the creative power of natural language in AI coding tools will shift the way developers write code and solve complex problems, fueling creativity and democratizing software development.
Idan Gazit, Senior Director of Research for GitHub Next, identifies new modalities of interaction, or patterns in the way code is expressed to and written by developers. One of those is iteration, which is most often seen in chat functionalities. Developers can ask the model for an answer, and if it isn’t quite right, refine the suggestions through experimentation.
He says, “When it comes to building AI applications today, the place to really distinguish the quality of one tool from another is through the tool’s DevEx.”
To show how GitHub Copilot can help developers build more efficiently, here’s an example of a developer learning how to prompt the AI pair programmer to generate her desired result.
A vague prompt like, “Draw an ice cream cone with ice cream using p5.js,” resulted in an image that looked like a bulls-eye target sitting on top of a stand:
A revised prompt that specified details about the desired image, like “The ice cream cone will be a triangle with the point facing down, wider point at the top,” helped the developer to generate her intended result, and saved her from writing code from scratch:
| What does it take to design products with AI? Learn more from Gazit about patterns and practices for making AI-powered products. |
Tip 2: Identify and define a developer’s pain points
Designing for developers means placing their needs, preferences, and workflows at the forefront. Adrián Mato, who leads GitHub Copilot’s design team, explains, “It’s hard to design a good product if you don’t have an opinion. That’s why you need to ask questions, embrace user feedback, and do the research to fully understand the problem space you’re working in, and how developers think and operate.”
Keeping devs in the flow
For example, when designing GitHub Copilot, our designers had to make decisions about optionality, which is when an AI model provides a developer with various code completion suggestions (like GitHub Copilot does through ghost text) that the developer can review, accept, or reject. These decisions are important because writing software is like building a house of cards—tiny distractions can shatter a developer’s flow and productivity, so designers have to make sure the UX for coding suggestions makes a developer’s job easier and not the other way around.
Considering ghost text and going modeless
When GitHub Copilot launched as a technical preview in June 2021 and became generally available in June 2022, ghost text—the gray text that flashes a coding suggestion while you type—was lauded as keeping developers in the flow because it made the code completion suggestions easy to use or ignore. In other words, the AI capability is modeless: Users don’t have to navigate away from the IDE to use it, and the AI works in the background.
GitHub Copilot also suggests code in a way that allows the user to continuously type: either press tab to accept a suggestion or keep typing to ignore the suggestion. “Modeless AI is like riding an electric bike with a pedal assist rather than one where you have to switch gears on the handlebar,” Gazit explains.
When it comes to addressing developer pain points, this pedal assist is essential to keeping them in the flow and doing their best work.
Tip 3: Gather meaningful developer feedback
Knowing how to ask for the right kind of feedback is critical to designing a useful product. To keep bias from creeping into each part of the research process, Grace Vorreuter, Principal Researcher for GitHub’s Communities team, shares unbiased interview questions to get you started on the right path:
- What’s the hardest part about [x situation] today? This question helps to contextualize the problem.
- Can you tell me a story about the last time that happened? Stories allow researchers to dive deeper into user problems, learn context, empathize with customers, and remember what information they shared.
- Can you say more about why that was difficult? This question uncovers a deeper layer of the problem.
- What, if anything, have you tried to solve that problem? If the user shares they’ve already looked for a solution, it’s a signal that this is a significant problem.
- What’s not ideal about your current solution? This question can reveal an opportunity space.
- How often do you experience this problem? This gives a sense of the size of the problem.
Tip 4: Design for imperfection
Rosenkilde’s justification of the double trigger in the technical preview of GitHub Copilot CLI reinforces an important fact: LLMs can be wrong. While no tool is perfect, the ability of LLMs to hallucinate, or convincingly spit out false information, is important to keep in mind.
Though models will improve in the future—and we’ll discover better prompting strategies that generate reliable responses—we don’t have to wait until tomorrow to build. We can innovate responsibly today by designing around the capabilities of current models.
“We have to design apps not only for models whose outputs need evaluation by humans, but also for humans who are learning how to interact with AI,” Gazit says. “Ghost text is one of the first mechanisms that make evaluation cheap and seamless, in that wrong suggestions are ignorable. We have to design more user experiences that are forgiving of today’s imperfect models.”
A well-designed tool helps to establish a foundation of trust. “But it doesn’t compensate for leading someone awry, which can happen with generative AI,” adds Manuel Muñoz Solera, Senior Director of Product Design at GitHub. Developers expect an AI model to pull in all the right context to answer a query, every single time, but there’s a technical boundary in that today’s LLMs process a limited amount of context. That poses a tough but interesting challenge when designing the UX, which needs to manage a user’s expectations while still providing a solution.
Tip 5: Recognize bias in your research
Vorreuter also shares pointers for recognizing different kinds of bias that surface during user research:
- Confirmation bias is when data is analyzed and interpreted to confirm hypotheses and expectations. To avoid this bias in research, try to invalidate your hypothesis, and report on all findings (positive and negative) to avoid cherry-picking results.
For example, let’s say your hypothesis is that AI coding tools make developers more collaborative. A question like “Do you agree or disagree that AI coding tools make you more collaborative?” assumes part of your hypothesis—that all developers use AI coding tools—is true. The question also forces a yes or no response. On the other hand, a question like “In what ways do you imagine a world with AI coding tools will impact collaboration within teams?” encourages a nuanced response.
-
Leading language is when a question or task uses certain wording that provides a hint for a particular response or behavior the interviewer is looking for (like “How much does waiting for CI pipelines to run negatively impact your day?”). To avoid this trap, prepare a discussion guide that includes open-ended, non-leading questions (such as “Which of the following do you spend the most time doing on any given day?” followed by a list of options to rank in order). Then, ask for peer feedback on your discussion guide and hold a pilot interview, after which you can iterate on your questions.
-
Selection bias is when study participants haven’t been selected at random, so certain kinds of people, more than others, are included in the study and skew the results. To avoid this bias, refer to your study’s objectives when deciding what kind of customers to solicit. Be proactive and actively seek out the folks you’re looking for rather than letting people self-select into giving feedback.
This list isn’t exhaustive, nor are all the solutions fool proof—but at GitHub, we’ve found these three tips to be incredibly helpful reminders about how bias can cloud our approach to product design.
Tip 6: Allow developers to customize context views
Developers need easy access to a lot of different information when writing code—or, said another way, context is key for developers. A common design question is how much information and context should be displayed on the UI, and how to design a UX that makes context switching feel seamless. We found that when developers are given options to tailor a product to their preferences and requirements, their DevEx becomes personalized and comfortable.
According to Nicolas Solerieu, Senior Site Designer at GitHub, minimizing the amount of visual variation and elements to scan can create a feeling of immersion even when the developer has to context switch. But sometimes developers need rapid data consumption to find the necessary information.
Developer tools should allow users to view information at different scales, from a general view that makes an entire workflow visible to a granular one that highlights an individual problem.
Tip 7: Design for extensibility
Sometimes it’s the ability to amplify the capabilities of an existing tool—instead of building a new one—that improves a developer’s workflow. Because developers typically use a large number of tools, offering smooth integrations pays dividends for the developer experience.
Well-written documentation and APIs, for example, are critical to a developer’s understanding, set up, and extensibility of a tool. When tools are built with extensibility and integration in mind, they can be optimized for a developer’s custom needs, and, ultimately, enable efficient application builds and deployment.
|
Check out our guides to improve your documentation and APIs:
|
Tip 8: Design for accessibility
A good reminder when designing accessible tooling is that designs for users with disabilities also benefit users without disabilities in extraordinary circumstances. For example, designing a system for those with visual impairments can also help someone struggling to read an e-reader in bright sunlight. Rachel Cohen, Director of Design Infrastructure at GitHub, encourages designers to embrace a “shift-left” mindset and consider the requirements of individuals with disabilities earlier in the design process. The result is more resilient, inclusive, and forward-thinking solutions.
Want to advance your organization’s accessibility practices? Apply these tactics and lessons from GitHub’s Design team.
Tip 9: Prioritize performance over flashy features
Striking a balance between adding new features and optimizing existing ones can be challenging, but the priority should always be to maintain or improve the tool’s performance.
“Developer tooling is very specific in that the available technology is applied to solve an identified problem in the best way possible,” according to Muñoz Solera. “The technology is used with purpose and isn’t just used to drive product engagement.”
|
GitHub Copilot X is our envisioned future of AI-powered software development. Discover what’s new. |
Tip 10: Use a tool’s safeguards to upskill developers and improve AI models
AI applications should have a revision workflow that allows developers to revise an output from the AI model. This is the workflow we built into GitHub Copilot’s ghost text UX and GitHub Copilot Chat.
In GitHub Copilot for CLI, explanations comprise the revision workflow. Rosenkilde says that a revision workflow not only helps to mitigate risk, but also helps to educate the developer: “The suggested command might be an arcane shell script, so maybe the developer doesn’t understand what that command will do once it runs. The explanation is there to help guide the developer through the shell command’s function and verify it against the original problem the developer is trying to solve.”
A revision workflow is also a way for a developer to send feedback to the AI model. Feedback mechanisms built into UIs include the acceptance or ignore rate of AI-generated coding suggestions, the option for users to regenerate a response, and the ability for users to recover when a model falters. “We’re still in an experimental phase with generative AI,” Muñoz Solera says, “so we need to design AI tools that make it easy for developers to signal when the quality of the model’s output isn’t there.”
The path forward
Designers, engineers, and users of AI tools are starting to move beyond the shock value of generative AI models: They’re moving toward understanding the technology and, consequently, becoming more discerning about its use cases.
Here’s what we learned after three years of conceptualizing, designing, and extending AI-powered developer tools, like GitHub Copilot and GitHub Copilot Chat: There’s a lot more to discover.
We hope that sharing these tips will help to accelerate collective learning during this new age of software development.
From the outside, innovation looks like making giant leaps of progress. But innovation from the inside is repetition and making small steps forward.
Learn more about generative AI coding tools and LLMS
- What developers need to know about generative AI
- How generative AI is changing the way developers work
- How GitHub Copilot is getting better at understanding your code
- Working with the LLMs behind GitHub Copilot
The post A guide to designing and shipping AI developer tools appeared first on The GitHub Blog.
]]>