In probability theory and statistics, the Bernoulli distribution, named after Swiss mathematician Jacob Bernoulli,[1] is the discrete probability distribution of a random variable which takes the value 1 with probability and the value 0 with probability . Less formally, it can be thought of as a model for the set of possible outcomes of any single experiment that asks a yes–no question. Such questions lead to outcomes that are Boolean-valued: a single bit whose value is success/yes/true/one with probability p and failure/no/false/zero with probability q. It can be used to represent a (possibly biased) coin toss where 1 and 0 would represent "heads" and "tails", respectively, and p would be the probability of the coin landing on heads (or vice versa where 1 would represent tails and p would be the probability of tails). In particular, unfair coins would have
|
Probability mass function 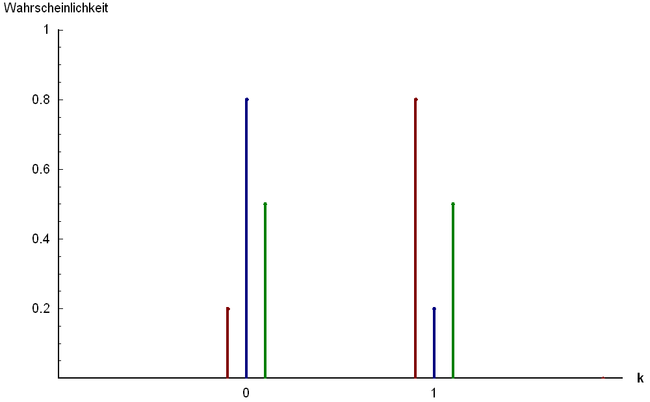
Three examples of Bernoulli distribution: and
and
and | |||
| Parameters |
| ||
|---|---|---|---|
| Support | |||
| PMF | |||
| CDF | |||
| Mean | |||
| Median | |||
| Mode | |||
| Variance | |||
| MAD | |||
| Skewness | |||
| Excess kurtosis | |||
| Entropy | |||
| MGF | |||
| CF | |||
| PGF | |||
| Fisher information | |||
The Bernoulli distribution is a special case of the binomial distribution where a single trial is conducted (so n would be 1 for such a binomial distribution). It is also a special case of the two-point distribution, for which the possible outcomes need not be 0 and 1. [2]
Properties
editIf is a random variable with a Bernoulli distribution, then:
The probability mass function of this distribution, over possible outcomes k, is
This can also be expressed as
or as
The Bernoulli distribution is a special case of the binomial distribution with [4]
The kurtosis goes to infinity for high and low values of but for the two-point distributions including the Bernoulli distribution have a lower excess kurtosis, namely −2, than any other probability distribution.
The Bernoulli distributions for form an exponential family.
The maximum likelihood estimator of based on a random sample is the sample mean.
Mean
editThe expected value of a Bernoulli random variable is
This is due to the fact that for a Bernoulli distributed random variable with and we find
Variance
editThe variance of a Bernoulli distributed is
We first find
From this follows
With this result it is easy to prove that, for any Bernoulli distribution, its variance will have a value inside .
Skewness
editThe skewness is . When we take the standardized Bernoulli distributed random variable we find that this random variable attains with probability and attains with probability . Thus we get
Higher moments and cumulants
editThe raw moments are all equal due to the fact that and .
The central moment of order is given by
The first six central moments are
The higher central moments can be expressed more compactly in terms of and
The first six cumulants are
Entropy and Fisher's Information
editEntropy
editEntropy is a measure of uncertainty or randomness in a probability distribution. For a Bernoulli random variable with success probability and failure probability , the entropy is defined as:
The entropy is maximized when , indicating the highest level of uncertainty when both outcomes are equally likely. The entropy is zero when or , where one outcome is certain.
Fisher's Information
editFisher information measures the amount of information that an observable random variable carries about an unknown parameter upon which the probability of depends. For the Bernoulli distribution, the Fisher information with respect to the parameter is given by:
Proof:
- The Likelihood Function for a Bernoulli random variable is:
This represents the probability of observing given the parameter .
- The Log-Likelihood Function is:
- The Score Function (the first derivative of the log-likelihood w.r.t. is:
- The second derivative of the log-likelihood function is:
- Fisher information is calculated as the negative expected value of the second derivative of the log-likelihood:
It is maximized when , reflecting maximum uncertainty and thus maximum information about the parameter .
Related distributions
edit- If are independent, identically distributed (i.i.d.) random variables, all Bernoulli trials with success probability p, then their sum is distributed according to a binomial distribution with parameters n and p:
- The Bernoulli distribution is simply , also written as
- The categorical distribution is the generalization of the Bernoulli distribution for variables with any constant number of discrete values.
- The Beta distribution is the conjugate prior of the Bernoulli distribution.[5]
- The geometric distribution models the number of independent and identical Bernoulli trials needed to get one success.
- If , then has a Rademacher distribution.
See also
edit- Bernoulli process, a random process consisting of a sequence of independent Bernoulli trials
- Bernoulli sampling
- Binary entropy function
- Binary decision diagram
References
edit- ^ Uspensky, James Victor (1937). Introduction to Mathematical Probability. New York: McGraw-Hill. p. 45. OCLC 996937.
- ^ Dekking, Frederik; Kraaikamp, Cornelis; Lopuhaä, Hendrik; Meester, Ludolf (9 October 2010). A Modern Introduction to Probability and Statistics (1 ed.). Springer London. pp. 43–48. ISBN 9781849969529.
- ^ a b c d Bertsekas, Dimitri P. (2002). Introduction to Probability. Tsitsiklis, John N., Τσιτσικλής, Γιάννης Ν. Belmont, Mass.: Athena Scientific. ISBN 188652940X. OCLC 51441829.
- ^ McCullagh, Peter; Nelder, John (1989). Generalized Linear Models, Second Edition. Boca Raton: Chapman and Hall/CRC. Section 4.2.2. ISBN 0-412-31760-5.
- ^ Orloff, Jeremy; Bloom, Jonathan. "Conjugate priors: Beta and normal" (PDF). math.mit.edu. Retrieved October 20, 2023.
Further reading
edit- Johnson, N. L.; Kotz, S.; Kemp, A. (1993). Univariate Discrete Distributions (2nd ed.). Wiley. ISBN 0-471-54897-9.
- Peatman, John G. (1963). Introduction to Applied Statistics. New York: Harper & Row. pp. 162–171.
External links
edit- "Binomial distribution", Encyclopedia of Mathematics, EMS Press, 2001 [1994].
- Weisstein, Eric W. "Bernoulli Distribution". MathWorld.
- Interactive graphic: Univariate Distribution Relationships.