Desoxyribonukleinsäure
Desoxyribonukleinsäure (), meist kurz als DNA (Abkürzung für englisch deoxyribonucleic acid), seltener auch als DNS abgekürzt, ist eine aus unterschiedlichen Desoxyribonukleotiden aufgebaute Nukleinsäure. Sie trägt die Erbinformation bei allen Lebewesen und den DNA-Viren. Das langkettige Polynukleotid enthält in Abschnitten von Genen besondere Abfolgen seiner Nukleotide. Diese DNA-Abschnitte dienen als Matrizen für den Aufbau entsprechender Ribonukleinsäuren (RNA), wenn genetische Information von DNA in RNA umgeschrieben wird (siehe Transkription). Die hierbei an der DNA-Vorlage aufgebauten RNA-Stränge erfüllen unterschiedliche Aufgaben; sie sind als rRNA (englisch ribosomal RNA), als tRNA (englisch transfer RNA) und als mRNA (englisch messenger RNA) an der Biosynthese von Proteinen beteiligt (siehe Proteinbiosynthese). Im Falle einer messenger- oder Boten-RNA (mRNA) stellt die Abfolge von Nukleinbasen die Bauanleitung für ein Protein dar.
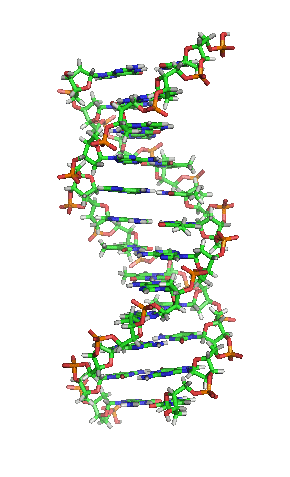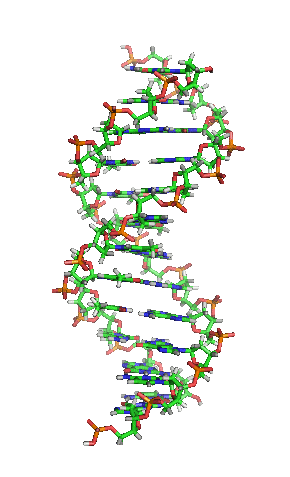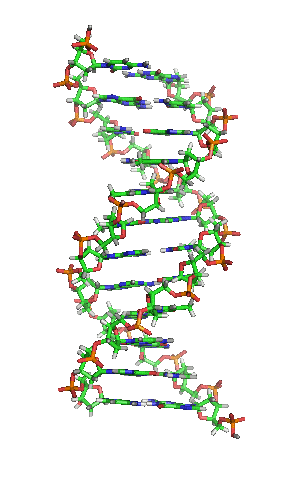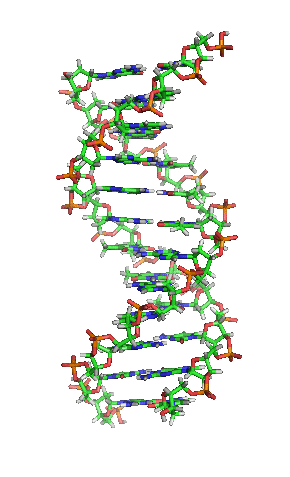
Die Grundbausteine von DNA-Strängen sind vier verschiedene Nukleotide, die jeweils aus einem Phosphatrest, dem Zucker Desoxyribose sowie einer von vier Nukleinbasen (Adenin, Thymin, Guanin und Cytosin; oft mit A, T, G und C abgekürzt) bestehen. Die Abfolge von Basen (Nukleotidsequenz) in bestimmten DNA-Strangabschnitten enthält Information. Umgeschrieben in den Einzelstrang einer mRNA gibt deren Basensequenz bei der Proteinbiosynthese die Abfolge von Aminosäuren (Aminosäuresequenz) im zu bildenden Protein vor. Hierbei wird drei aufeinanderfolgenden Basen – je einem Basentriplett als Codon – jeweils eine bestimmte Aminosäure zugeordnet und diese mit der vorigen verknüpft, sodass ein Polypeptid entsteht. So werden an einem Ribosom mithilfe von tRNA entsprechend dem genetischen Code Bereiche der Basensequenz in eine Aminosäurensequenz übersetzt (siehe Translation).
Das Genom einer Zelle liegt zumeist als DNA-Doppelstrang vor, bei dem die beiden basenpaarend einander komplementären Stränge räumlich die Form einer Doppelhelix bilden (siehe Abbildung). Bei der Replikation werden sie entwunden und getrennt jeweils durch Basenpaarung wieder komplementär ergänzt, sodass anschließend zwei (nahezu) identische doppelsträngige DNA-Moleküle vorliegen. Fehler beim Replikationsvorgang sind eine Quelle von Mutationen, die nach Kernteilung und Zellteilung in entstandenen Zellen als Veränderung genetischer Information vorliegen und weitergegeben werden können.
In den Zellen von Eukaryoten, zu denen Pflanzen, Tiere und Pilze gehören, ist der Großteil der DNA im Zellkern (lateinisch nucleus, daher nukleäre DNA oder nDNA) als Chromosomen organisiert. Ein kleiner Teil befindet sich in den Mitochondrien und wird dementsprechend mitochondriale DNA (mtDNA) genannt. Pflanzen und Algen haben außerdem DNA in Photosynthese betreibenden Organellen, den Chloroplasten bzw. Plastiden (cpDNA). Bei Bakterien und Archaeen – den Prokaryoten, die keinen Zellkern besitzen – liegt die DNA im Cytoplasma meist zirkulär vor (siehe Bakterienchromosom). Manche Viren speichern ihre genetische Information in RNA statt in DNA (siehe RNA-Virus).
Bezeichnung
BearbeitenDie Bezeichnung Desoxyribonukleinsäure ist ein Wort, das sich aus mehreren Komponenten zusammensetzt: des (von des-), oxy (erste beiden Sprechsilben von Oxygenium für Sauerstoff), ribo (erste beiden Silben von Ribose) – somit Desoxyribo (für Desoxyribose) – und nukleinsäure (von Nuklein und Säure). Im deutschen Sprachgebrauch wird die Desoxyribonukleinsäure inzwischen überwiegend mit der englischen Abkürzung für deoxyribonucleic acid als DNA bezeichnet, während die Abkürzung DNS nach dem Duden als „veraltend“[1] gilt.
Entdeckungsgeschichte
Bearbeiten
1869 entdeckte der Schweizer Arzt Friedrich Miescher in einem Extrakt aus Eiter eine durch milde Säurebehandlung aus den Zellkernen der Leukozyten[2] gewonnene Substanz, die er Nuklein nannte. Miescher arbeitete damals im Labor von Felix Hoppe-Seyler im Tübinger Schloss.[3] 1892 (bzw. 1897 posthum, nachdem der zu Grunde liegende Brief veröffentlicht wurde) führte der „späte“ Miescher auf Basis seiner biochemischen Erkenntnisse hinsichtlich der Komplexität von Nukleinen und Proteinen als erster den Schrift- oder Code-Vergleich für den noch zu entdeckenden Träger der Erbinformation als Forschungshypothese in die Genetik ein.[4][5] 1889 isoliert der Deutsche Richard Altmann aus dem Nuklein Proteine und die Nukleinsäure.[6] Weitere Erkenntnisse zur Nukleinsäure gehen auf die Arbeiten von Albrecht Kossel (siehe „Die Entdeckung der Nukleinbasen“) zurück, für die er 1910 mit dem Nobelpreis für Physiologie oder Medizin ausgezeichnet wurde. Im Jahr 1885 teilte er mit, dass aus einer größeren Menge Rinder-Bauchspeicheldrüse eine stickstoffreiche Base mit der Summenformel C5H5N5 isoliert wurde, für die er, abgeleitet von dem griechischen Wort „aden“ für Drüse, den Namen Adenin vorschlug. 1891 konnte Kossel (nach Altmanns Verfahren) Hefe-Nukleinsäure herstellen und Adenin und Guanin als Spaltprodukte nachweisen. Es stellte sich heraus, dass auch ein Kohlenhydrat Bestandteil der Nukleinsäure sein musste. Kossel wählte für die basischen Substanzen Guanin und Adenin sowie seine Derivate den Namen Nucleinbasen.
1893 berichtete Kossel, dass er aus den Thymusdrüsen des Kalbes Nukleinsäure gewonnen und ein gut kristallisiertes Spaltprodukt erhalten hatte, für das er den Namen Thymin vorschlug. 1894 isolierte er aus den Thymusdrüsen eine weitere (basische) Substanz. Kossel gab ihr den Namen Cytosin.
Nachdem am Ende des 19. Jahrhunderts – im Wesentlichen durch die Synthesen Emil Fischers – die Strukturformeln des Guanins und Adenins als Purinkörper und des Thymins als Pyrimidinkörper endgültig aufgeklärt worden waren, konnte Kossel mit Hermann Steudel (1871–1967) auch die Strukturformel der Nukleinbase Cytosin als Pyrimidinkörper zweifelsfrei ermitteln. Es hatte sich inzwischen erwiesen, dass Guanin, Adenin sowie Thymin und Cytosin in allen entwicklungsfähigen Zellen zu finden sind.
Die Erkenntnisse über diese vier Nukleinbasen sollten für die spätere Strukturaufklärung der DNA von wesentlicher Bedeutung sein. Es war Albrecht Kossel, der sie – zusammen mit einem Kohlenhydrat und der Phosphorsäure – eindeutig als Bausteine der Nukleinsäure charakterisierte:
„Es gelang mir, eine Reihe von Bruchstücken zu erhalten … welche durch eine ganz eigentümliche Ansammlung von Stickstoffatomen gekennzeichnet sind. Es sind hier nebeneinander … das Cytosin, das Thymin, das Adenin und das Guanin.“ (Nobelvortrag am 12. Dezember 1910).
Der aus Litauen stammende Biochemiker Phoebus Levene schlug eine kettenartige Struktur der Nukleinsäure vor, in welcher die Nukleotide durch die Phosphatreste zusammengefügt sind und sich wiederholen.[7] 1929 konnte er in Zusammenarbeit mit dem russischen Physiologen Efim London (1869–1932) den Zuckeranteil der „tierische Nukleinsäure“ als Desoxyribose identifizieren (J. Biol. Chem.1929, 83. Seiten 793-802). [5a] Erst nachfolgend wurde sie als Desoxyribonukleinsäure bezeichnet. Es wurde erkannt, dass sie auch in pflanzlichen Zellkernen vorkommt.
Als wirksamer Bestandteil der Chromosomen bzw. des Kernchromatins wurde die DNA bereits 1932 von K. Voit und Hartwig Kuhlenbeck angesehen.[8] 1937 publizierte William Astbury erstmals Röntgenbeugungsmuster, die auf eine repetitive Struktur der DNA hinwiesen.[9]
1943 wies Oswald Avery nach, dass die Transformation von Bakterien, das heißt die Weitergabe erblicher Information von einem Bakterien-Stamm auf einen anderen (heute horizontaler Gentransfer genannt), auf der Übertragung von DNA beruht.[10] Dies widersprach der damals noch allgemein favorisierten Annahme, dass nicht die DNA, sondern Proteine die Träger der Erbinformation seien. Unterstützung in seiner Interpretation erhielt Avery 1952, als Alfred Day Hershey und Martha Chase nachwiesen, dass DNA die Erbinformation des T2-Phagen enthält.[11]
Den strukturellen Aufbau der DNA zu entschlüsseln und im Modell nachzubilden, gelang dem US-Amerikaner James Watson und dem Briten Francis Crick am 28. Februar 1953.[12][13] Ihre Entdeckung publizierten sie in der April-Ausgabe 1953 des Magazins Nature in ihrem berühmten Artikel Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acid.[14] Watson kam 1951 nach England, nachdem er ein Jahr zuvor an der Indiana University Bloomington in den USA promoviert hatte. Er hatte zwar ein Stipendium für Molekularbiologie bekommen, beschäftigte sich aber vermehrt mit der Frage des menschlichen Erbguts. Crick widmete sich in Cambridge gerade erfolglos seiner Promotion über die Kristallstruktur des Hämoglobinmoleküls, als er 1951 Watson traf.
Zu dieser Zeit war bereits ein erbitterter Wettlauf um die Struktur der DNA entbrannt, an dem sich neben anderen auch Linus Pauling am California Institute of Technology (Caltech) beteiligte. Watson und Crick waren eigentlich anderen Projekten zugeteilt worden und besaßen kein bedeutendes Fachwissen in Chemie. Sie bauten ihre Überlegungen auf den Forschungsergebnissen der anderen Wissenschaftler auf. Watson sagte, er wolle das Erbgut entschlüsseln, ohne Chemie lernen zu müssen. In einem Gespräch mit dem renommierten Chemiker und Ersteller der Chargaff-Regeln, Erwin Chargaff, vergaß Crick wichtige Molekülstrukturen, und Watson machte im selben Gespräch unpassende Anmerkungen, die seine Unkenntnis auf dem Gebiet der Chemie verrieten. Chargaff nannte die jungen Kollegen im Anschluss „wissenschaftliche Clowns“.[15]
Watson besuchte Ende 1952 am King’s College in London Maurice Wilkins, der ihm DNA-Röntgenaufnahmen von Rosalind Franklin zeigte. Das geschah ohne Wissen und gegen den Willen von R. Franklin.[16][17] Watson sah sofort, dass es sich bei dem Molekül um eine Doppel-Helix handeln musste; Franklin hatte dies natürlich ebenfalls erkannt und eine mathematische Analyse der Beugungsdaten durchgeführt. Auch der Bericht mit den Berechnungsergebnissen von Franklins Analyse wurde heimlich an Watson und Crick weitergegeben. Damit gelang es Watson und Crick in kürzester Zeit, die Molekularstruktur am Cavendish-Laboratorium der Universität von Cambridge korrekt herzuleiten. Ihr Doppelhelix-Modell der DNA mit den Basenpaaren in der Mitte wurde am 25. April 1953 in der Zeitschrift Nature publiziert.[18]
Diese denkwürdige Veröffentlichung enthält gegen Ende den Satz „It has not escaped our notice that the specific pairing we have postulated immediately suggests a possible copying mechanism for the genetic material“. („Es ist unserer Aufmerksamkeit nicht entgangen, dass die spezifische Paarung, die wir als gegeben voraussetzen, unmittelbar auf einen möglichen Vervielfältigungsmechanismus für das genetische Material schließen lässt.“)
„Für ihre Entdeckungen über die Molekularstruktur der Nukleinsäuren und ihre Bedeutung für die Informationsübertragung in lebender Substanz“ erhielten Watson und Crick zusammen mit Maurice Wilkins 1962 den Nobelpreis für Medizin.[19] Rosalind Franklin, deren Röntgenbeugungsdiagramme wesentlich zur Entschlüsselung der DNA-Struktur beigetragen hatten, war zu diesem Zeitpunkt bereits verstorben und konnte daher nicht mehr nominiert werden. Ihr Anteil an der Entdeckung wurde vom Nobelkomitee nicht erwähnt.
Für weitere geschichtliche Informationen zur Entschlüsselung der Vererbungsvorgänge siehe „Forschungsgeschichte des Zellkerns“ sowie „Forschungsgeschichte der Chromosomen“ und „Chromosomentheorie der Vererbung“.
Aufbau und Organisation
BearbeitenBausteine
BearbeitenDie Desoxyribonukleinsäure ist ein langes Kettenmolekül (Polymer) aus vielen Bausteinen, die man Desoxyribonukleotide oder kurz Nukleotide nennt. Jedes Nukleotid hat drei Bestandteile: Phosphorsäure bzw. Phosphat, den Zucker Desoxyribose sowie eine heterozyklische Nukleobase oder kurz Base. Die Desoxyribose- und Phosphorsäure-Untereinheiten sind bei jedem Nukleotid gleich. Sie bilden das Rückgrat des Moleküls. Einheiten aus Base und Zucker (ohne Phosphat) werden als Nukleoside bezeichnet.
Die Phosphatreste sind aufgrund ihrer negativen Ladung hydrophil, sie geben DNA in wässriger Lösung insgesamt eine negative Ladung. Da diese negativ geladene, in Wasser gelöste DNA keine weiteren Protonen abgeben kann, handelt es sich streng genommen nicht (mehr) um eine Säure. Der Begriff Desoxyribonukleinsäure bezieht sich auf einen ungeladenen Zustand, in dem Protonen an die Phosphatreste angelagert sind.
Bei der Base kann es sich um ein Purin, nämlich Adenin (A) oder Guanin (G), oder um ein Pyrimidin, nämlich Thymin (T) oder Cytosin (C), handeln. Da sich die vier verschiedenen Nukleotide nur durch ihre Base unterscheiden, werden die Abkürzungen A, G, T und C auch für die entsprechenden Nukleotide verwendet.
Die fünf Kohlenstoffatome einer Desoxyribose sind von 1' (sprich Eins Strich) bis 5' nummeriert. Am 1'-Ende dieses Zuckers ist die Base gebunden. Am 5'-Ende hängt der Phosphatrest. Genau genommen handelt es sich bei der Desoxyribose um die 2-Desoxyribose; der Name kommt daher, dass im Vergleich zu einem Ribose-Molekül eine alkoholische Hydroxygruppe (OH-Gruppe) an der 2'-Position fehlt (d. h. durch ein Wasserstoffatom ersetzt wurde).
An der 3'-Position ist eine OH-Gruppe vorhanden, welche die Desoxyribose über eine sogenannte Phosphodiester-Bindung mit dem 5'-Kohlenstoffatom des Zuckers des nächsten Nukleotids verknüpft (siehe Abbildung). Dadurch besitzt jeder sogenannte Einzelstrang zwei verschiedene Enden: ein 5'- und ein 3'-Ende. DNA-Polymerasen, die in der belebten Welt die Synthese von DNA-Strängen durchführen, können neue Nukleotide nur an die OH-Gruppe am 3'-Ende anfügen, nicht aber am 5'-Ende. Der Einzelstrang wächst also immer von 5' nach 3' (siehe auch DNA-Replikation weiter unten). Dabei wird ein Nukleosidtriphosphat (mit drei Phosphatresten) als neuer Baustein angeliefert, von dem zwei Phosphate in Form von Pyrophosphat abgespalten werden. Der verbleibende Phosphatrest des jeweils neu hinzukommenden Nukleotids wird mit der OH-Gruppe am 3'-Ende des letzten im Strang vorhandenen Nukleotids unter Wasserabspaltung verbunden. Die Abfolge der Basen im Strang codiert die genetische Information.
Die Doppelhelix
BearbeitenDNA kommt normalerweise als schraubenförmige Doppelhelix in einer Konformation vor, die B-DNA genannt wird. Zwei der oben beschriebenen Einzelstränge sind dabei aneinandergelagert, und zwar in entgegengesetzter Richtung: An jedem Ende der Doppelhelix hat einer der beiden Einzelstränge sein 3'-Ende, der andere sein 5'-Ende. Durch die Aneinanderlagerung stehen sich in der Mitte der Doppelhelix immer zwei bestimmte Basen gegenüber, sie sind „gepaart“. Die Doppelhelix wird hauptsächlich durch Stapelwechselwirkungen zwischen aufeinanderfolgenden Basen desselben Stranges stabilisiert (und nicht, wie oft behauptet, durch Wasserstoffbrückenbindungen zwischen den Strängen).
Es paaren sich immer Adenin und Thymin, die dabei zwei Wasserstoffbrücken ausbilden, oder Cytosin mit Guanin, die über drei Wasserstoffbrücken miteinander verbunden sind. Eine Brückenbildung erfolgt zwischen den Molekülpositionen 1═1 sowie 6═6, bei Guanin-Cytosin-Paarungen zusätzlich zwischen 2═2. Da sich immer die gleichen Basen paaren, lässt sich aus der Sequenz der Basen in einem Strang die des anderen Strangs ableiten, die Sequenzen sind komplementär (siehe auch: Basenpaar). Dabei sind die Wasserstoffbrücken fast ausschließlich für die Spezifität der Paarung verantwortlich, nicht aber für die Stabilität der Doppelhelix.
Da stets ein Purin mit einem Pyrimidin kombiniert wird, ist der Abstand zwischen den Strängen überall gleich, es entsteht eine regelmäßige Struktur. Die ganze Helix hat einen Durchmesser von ungefähr 2 nm und windet sich mit jedem Zuckermolekül um 0,34 nm weiter.
Die Ebenen der Zuckermoleküle stehen in einem Winkel von 36° zueinander, und eine vollständige Drehung wird folglich nach 10 Basen (360°) und 3,4 nm erreicht. DNA-Moleküle können sehr groß werden. Beispielsweise enthält das größte menschliche Chromosom 247 Millionen Basenpaare.[20]
Beim Umeinanderwinden der beiden Einzelstränge verbleiben seitliche Lücken, sodass hier die Basen direkt an der Oberfläche liegen. Von diesen Furchen gibt es zwei, die sich um die Doppelhelix herumwinden (siehe Abbildungen und Animation am Artikelanfang). Die „große Furche“ ist 2,2 nm breit, die „kleine Furche“ nur 1,2 nm.[21]
Entsprechend sind die Basen in der großen Furche besser zugänglich. Proteine, die sequenzspezifisch an die DNA binden, wie zum Beispiel Transkriptionsfaktoren, binden daher meist an der großen Furche.[22]
Auch manche DNA-Farbstoffe, wie zum Beispiel DAPI, lagern sich an einer Furche an.
Die kumulierte Bindungsenergie zwischen den beiden Einzelsträngen hält diese zusammen. Kovalente Bindungen sind hier nicht vorhanden, die DNA-Doppelhelix besteht also nicht aus einem Molekül, sondern aus zweien. Dadurch können die beiden Stränge in biologischen Prozessen zeitweise getrennt werden.
Neben der eben beschriebenen B-DNA existieren auch A-DNA sowie eine 1979 von Alexander Rich und seinen Kollegen am MIT erstmals auch untersuchte, linkshändige, sogenannte Z-DNA. Diese tritt besonders in G-C-reichen Abschnitten auf. Erst 2005 wurde über eine Kristallstruktur berichtet, welche Z-DNA direkt in einer Verbindung mit B-DNA zeigt und so Hinweise auf eine biologische Aktivität von Z-DNA liefert.[23] Die folgende Tabelle und die daneben stehende Abbildung zeigen die Unterschiede der drei Formen im direkten Vergleich.
| Strukturmerkmal | A-DNA | B-DNA | Z-DNA |
|---|---|---|---|
| Aufbau aus | Monomeren | Monomeren | Dimeren |
| Drehsinn der Helix | rechts | rechts | links |
| Durchmesser (ca.) | 2,6 nm | 2,37 nm | 1,8 nm |
| Helikale Windung pro Basenpaar (twist) | 32,7° | 34,3° | 30° |
| Basenpaare pro helikale Windung | 11 | 10 | 12 |
| Anstieg pro Base | 0,29 nm | 0,34 nm | 0,37 nm |
| Anstieg pro Windung (Ganghöhe) | 3,4 nm | 3,4 nm | 4,4 nm |
| Neigungswinkel der Basenpaare zur Achse | 20° | 6° | 7° |
| Große Furche | eng und tief |
breit und tief Tiefe: 0,85 nm |
flach |
| Kleine Furche | breit und flach |
eng und tief Tiefe: 0,75 nm |
eng und tief |
| Pyrimidinbasen (Cytosin/Thymin/Uracil) Zuckerkonformation Glykosidische Bindung |
C3'-endo anti |
C2'-endo anti |
C2'-endo anti |
| Purinbasen (Adenin/Guanin) Zuckerkonformation Glykosidische Bindung |
C3'-endo anti |
C2'-endo anti |
C3'-endo syn |
b) linksgängige Doppelhelix
Die Stapel der Basenpaare (base stackings) liegen nicht wie Bücher exakt parallel aufeinander, sondern bilden Keile, die die Helix in die eine oder andere Richtung neigen. Den größten Keil bilden Adenosine, die mit Thymidinen des anderen Stranges gepaart sind. Folglich bildet eine Serie von AT-Paaren einen Bogen in der Helix. Wenn solche Serien in kurzen Abständen aufeinander folgen, nimmt das DNA-Molekül eine gebogene bzw. eine gekrümmte Struktur an, welche stabil ist. Dies wird auch Sequenz-induzierte Beugung genannt, da die Beugung auch von Proteinen hervorgerufen werden kann (die sogenannte Protein-induzierte Beugung). Sequenzinduzierte Beugung findet man häufig an wichtigen Stellen im Genom.
Chromatin und Chromosomen
BearbeitenOrganisiert ist die DNA in der eukaryotischen Zelle in Form von Chromatinfäden, genannt Chromosomen, die im Zellkern liegen. Ein einzelnes Chromosom enthält von der Anaphase bis zum Beginn der S-Phase einen langen, durchgehenden DNA-Doppelstrang (in einem Chromatid). Am Ende der S-Phase besteht das Chromosom aus zwei identischen DNA-Fäden (in zwei Chromatiden).
Da ein solcher DNA-Faden mehrere Zentimeter lang sein kann, ein Zellkern aber nur wenige Mikrometer Durchmesser hat, muss die DNA zusätzlich komprimiert bzw. „gepackt“ werden. Dies geschieht bei Eukaryoten mit sogenannten Chromatinproteinen, von denen besonders die basischen Histone zu erwähnen sind. Sie bilden die Nukleosomen, um die die DNA auf der niedrigsten Verpackungsebene herumgewickelt wird. Während der Kernteilung (Mitose) wird jedes Chromosom zu seiner maximal kompakten Form kondensiert. Dadurch können sie mit dem Lichtmikroskop besonders gut in der Metaphase identifiziert werden.
Bakterielle und virale DNA
BearbeitenIn prokaryotischen Zellen liegt die doppelsträngige DNA in den bisher dokumentierten Fällen mehrheitlich nicht als lineare Stränge mit jeweils einem Anfang und einem Ende vor, sondern als zirkuläre Moleküle – jedes Molekül (d. h. jeder DNA-Strang) schließt sich mit seinem 3'- und seinem 5'-Ende zum Kreis. Diese zwei ringförmigen, geschlossenen DNA-Moleküle werden je nach Länge der Sequenz als Bakterienchromosom oder Plasmid bezeichnet. Sie befinden sich bei Bakterien auch nicht in einem Zellkern, sondern liegen frei im Plasma vor. Die Prokaryoten-DNA wird mit Hilfe von Enzymen (zum Beispiel Topoisomerasen und Gyrasen) zu einfachen „Supercoils“ aufgewickelt, die einer geringelten Telefonschnur ähneln. Indem die Helices noch um sich selbst gedreht werden, sinkt der Platzbedarf für die Erbinformation. In den Bakterien sorgen Topoisomerasen dafür, dass durch ständiges Schneiden und Wiederverknüpfen der DNA der verdrillte Doppelstrang an einer gewünschten Stelle entwunden wird (Voraussetzung für Transkription und Replikation). Viren enthalten je nach Typ als Erbinformation entweder DNA oder RNA. Sowohl bei den DNA- wie den RNA-Viren wird die Nukleinsäure durch eine Protein-Hülle geschützt.
Chemische und physikalische Eigenschaften der DNA-Doppelhelix
BearbeitenDie DNA ist bei neutralem pH-Wert ein negativ geladenes Molekül, wobei die negativen Ladungen auf den Phosphaten im Rückgrat der Stränge sitzen. Zwar sind zwei der drei sauren OH-Gruppen der Phosphate mit den jeweils benachbarten Desoxyribosen verestert, die dritte ist jedoch noch vorhanden und gibt bei neutralem pH-Wert ein Proton ab, was die negative Ladung bewirkt. Diese Eigenschaft macht man sich bei der Agarose-Gelelektrophorese zu Nutze, um verschiedene DNA-Stränge nach ihrer Länge aufzutrennen. Einige physikalische Eigenschaften wie die freie Energie und der Schmelzpunkt der DNA hängen direkt mit dem GC-Gehalt zusammen, sind also sequenzabhängig.
Stapelwechselwirkungen
BearbeitenFür die Stabilität der Doppelhelix sind hauptsächlich zwei Faktoren verantwortlich: die Basenpaarung zwischen komplementären Basen sowie Stapelwechselwirkungen (stacking interactions) zwischen aufeinanderfolgenden Basen.
Anders als zunächst angenommen,[14] ist der Energiegewinn durch Wasserstoffbrückenbindungen vernachlässigbar, da die Basen mit dem umgebenden Wasser ähnlich gute Wasserstoffbrückenbindungen eingehen können. Die Wasserstoffbrücken eines GC-Basenpaares tragen nur minimal zur Stabilität der Doppelhelix bei, während diejenigen eines AT-Basenpaares sogar destabilisierend wirken.[24] Stapelwechselwirkungen hingegen wirken nur in der Doppelhelix zwischen aufeinanderfolgenden Basenpaaren: Zwischen den aromatischen Ringsystemen der heterozyklischen Basen entsteht eine dipol-induzierte Dipol-Wechselwirkung, welche energetisch günstig ist. Somit ist die Bildung des ersten Basenpaares aufgrund des geringen Energiegewinnes und des -verlustes recht ungünstig, jedoch die Elongation (Verlängerung) der Helix ist energetisch günstig, da die Basenpaarstapelung unter Energiegewinn verläuft.[25]
Die Stapelwechselwirkungen sind jedoch sequenzabhängig und energetisch am günstigsten für gestapelte GC-GC, weniger günstig für gestapelte AT-AT. Die Unterschiede in den Stapelwechselwirkungen erklären hauptsächlich, warum GC-reiche DNA-Abschnitte thermodynamisch stabiler sind als AT-reiche, während Wasserstoffbrückenbildung eine untergeordnete Rolle spielt.[24]
Schmelzpunkt
BearbeitenDer Schmelzpunkt der DNA ist die Temperatur, bei der die Bindungskräfte zwischen den beiden Einzelsträngen überwunden werden und diese sich voneinander trennen. Dies wird auch als Denaturierung bezeichnet.
Solange die DNA in einem kooperativen Übergang denaturiert (der sich in einem enggefassten Temperaturbereich vollzieht), bezeichnet der Schmelzpunkt die Temperatur, bei der die Hälfte der Doppelstränge in Einzelstränge denaturiert ist. Von dieser Definition sind die korrekten Bezeichnungen „midpoint of transition temperature“ bzw. Mittelpunktstemperatur Tm abgeleitet.
Der Schmelzpunkt hängt von der jeweiligen Basensequenz in der Helix ab. Er steigt, wenn in ihr mehr GC-Basenpaare liegen, da diese entropisch günstiger sind als AT-Basenpaare. Das liegt nicht so sehr an der unterschiedlichen Zahl der Wasserstoffbrücken, welche die beiden Paare ausbilden, sondern viel mehr an den unterschiedlichen Stapelwechselwirkungen (stacking interactions). Die stacking-Energie zweier Basenpaare ist viel kleiner, wenn eines der beiden Paare ein AT-Basenpaar ist. GC-Stapel dagegen sind energetisch günstiger und stabilisieren die Doppelhelix stärker. Das Verhältnis der GC-Basenpaare zur Gesamtzahl aller Basenpaare wird durch den GC-Gehalt angegeben.
Da einzelsträngige DNA UV-Licht etwa 40 Prozent stärker absorbiert als doppelsträngige, lässt sich die Übergangstemperatur in einem Photometer gut bestimmen.
Wenn die Temperatur der Lösung unter Tm zurückfällt, können sich die Einzelstränge wieder aneinanderlagern. Dieser Vorgang heißt Renaturierung oder Hybridisierung. Das Wechselspiel von De- und Renaturierung wird bei vielen biotechnologischen Verfahren ausgenutzt, zum Beispiel bei der Polymerase-Kettenreaktion (PCR), bei Southern Blots und der In-situ-Hybridisierung.
Kreuzförmige DNA an Palindromen
BearbeitenEin Palindrom ist eine Folge von Nukleotiden, bei denen sich die beiden komplementären Stränge jeweils von rechts genauso lesen lassen wie von links.
Unter natürlichen Bedingungen (bei hoher Drehspannung der DNA) oder künstlich im Reagenzglas kann sich diese lineare Helix als Kreuzform (cruciform) herausbilden, indem zwei Zweige entstehen, die aus dem linearen Doppelstrang herausragen. Die Zweige stellen jeweils für sich eine Helix dar, allerdings bleiben am Ende eines Zweiges mindestens drei Nukleotide ungepaart. Beim Übergang von der Kreuzform in die lineare Helix bleibt die Basenpaarung wegen der Biegungsfähigkeit des Phosphodiester-Zucker-Rückgrates erhalten.
Die spontane Zusammenlagerung von komplementären Basen zu sog. Stamm-Schleifen-Strukturen wird häufig auch bei Einzelstrang-DNA oder -RNA beobachtet.
Nicht-Standard-Basen
BearbeitenGelegentlich werden in Viren und zellulären Organismen Abweichungen von den oben genannten vier kanonischen Basen (Standard-Basen) Adenin (A), Guanin (G), Thymin (T) und Cytosin (C) beobachtet; weitere Abweichungen können künstlich erzeugt werden.
Natürliche Nichtstandard-Basen
Bearbeiten- Uracil (U) wird normalerweise nicht in der DNA gefunden, es tritt lediglich als Abbauprodukt von Cytosin auf. In mehreren Bakteriophagen (bakteriellen Viren) wird Thymin jedoch durch Uracil ersetzt:[26][27]
- Bacillus-subtilis-Bakteriophage PBS1 (Spezies Bacillus-Virus PBS1, wissenschaftlich Takahashivirus PBS1) und „PBS2“ (vorgeschlagene Spezies „Bacillus-Phage PBS2“)[28] – beide Spezies sind vom Morphotyp der Myoviren.
- Yersinia-Phage phiR1-RT (Spezies Yersinia-Virus R1RT, wiss. Tegunavirus r1rt), Morphotyp Myoviren[29]
- „Staphylococcus-Phage S6“ (alias Staphylococcus aureus Bacteriophage 15, ebenfalls Morphotyp Myovirien)
Uracil wird auch in der DNA von Eukaryoten wie Plasmodium falciparum (Apicomplexa) gefunden. Es ist dort in relativ geringen Mengen vorhanden (7–10 Uracileinheiten pro Million Basen).[30]
- 5-Hydroxymethyldesoxyuridin (hm5dU) ersetzt Thymidin im Genom verschiedener Bacillus-Phagen der Spezies Bacillus-Virus SPO1 (wiss. Okubovirus SPO1, Familie Herelleviridae und Morphotyp Siphoviren.[31][32] Es sind dies die Phagen SPO1, SP8, SP82, „Phi-E“ alias „ϕe“ und „2C“)[33][34]
- 5-Dihydroxypentauracil (DHPU, mit Nukleotid 5-dihydroxypentyl-dUMP, DHPdUMP) wurde als Ersatz für Thymidin im Bacillus-Phagen SP15 (auch SP-15, Spezies Thornevirus SP15, Morphotyp Myoviren)[32][35] beschrieben.[33][36][37][38]
- Beta-d-glucopyranosyloxymethyluracil (Base J), ebenfalls eine modifizierte Form von Uracil, wurde in verschiedenen Organismen gefunden: Den Flagellaten Diplonema und Euglena (beide Excavata: Euglenozoa) sowie allen Gattungen der Kinetoplastiden.[39] Die Biosynthese von J erfolgt in zwei Schritten: Im ersten Schritt wird ein spezifisches Thymidin in DNA in Hydroxymethyldesoxyuridin (HOMedU) umgewandelt, im zweiten wird HOMedU zu J glykosyliert.[40] Es gibt einige Proteine, die spezifisch an diese Base binden.[41][42][43] Diese Proteine scheinen entfernte Verwandte des Tet1-Onkogens zu sein, das an der Pathogenese der akuten myeloischen Leukämie beteiligt ist.[44] J scheint als Terminationssignal für RNA-Polymerase II zu wirken.[45][46]
- 2,6-Diaminopurin (alias 2-Aminoadenin, Base D oder X, DAP): 1976 wurde festgestellt, dass der „Cyanobacteria-Phage S-2L“ („Cyanophage S-2L“, informelle Gattung „Cyanostylovirus“, evtl. Familie „Cyanostyloviridae“ oder „Styloviridae“, Morphotyp Siphoviren),[47][48][49][50][51][52] dessen Wirte Spezies der Gattung Synechocystis sind, alle Adenosinbasen in seinem Genom durch 2,6-Diaminopurin ersetzt.[53][38] Drei weitere Untersuchungen folgten im Jahr 2021, eine Zusammenfassung findet sich auf sciencealert (Mai 2021).[54] Ähnliches gilt für „Acinetobacter-Phage SH-Ab 15497“ (en. „Acinetobacter phage SH-Ab 15497“),[55] ebenfalls Morphotyp Siphoviren, und weitere Vertreter dieses Morphotyps sowie dem der Podoviren.[56]
- Wie 2016 herausgefunden wurde, ist 2'-Desoxyarchaeosin (dG+) im Genom mehrerer Bakterien und im Escherichia-Phagen 9g (alias Enterobacteria-Phage 9g, Spezies Escherichia-Virus 9g, wiss. Nonagvirus nv9g, Unterfamilie Queuovirinae, Morphotyp Siphoviren) vorhanden.[57][58]
- 6-Methylisoxanthopterin
- 5-Hydroxyuracil
Natürliche modifizierte Basen (Methylierungen u. a.)
BearbeitenIn natürlicher DNA kommen auch modifizierte Basen vor. Insbesondere werden Methylierungen der kanonischen Basen im Rahmen der Epigenetik untersucht:
- Zunächst wurde im Jahr 1925 5-Methylcytosin (m5C) im Genom von Mycobacterium tuberculosis gefunden.[59] Im Genom des Xanthomonas oryzae-Bakteriophagen Xp12 (Xanthomonas phage Xp12), Gattung Bosavirus, Familie Mesyanzhinovviridae, Morphotyp Siphoviren)[60] und des Halovirus ΦH (Spezies Halobacterium-Virus phiH, wiss. Myohalovirus phiH, Familie Vertoviridae, Morphotyp Myoviren) ist das gesamte Cystosin-Kontingent durch 5-Methylcytosin ersetzt.[61][62]
- Einen kompletten Ersatz von Cytosin durch 5-Glycosylhydroxymethylcytosin (syn. Glycosyl-5-hydroxymethylcytosin) in den Phagen T2, T4 und T6 der Spezies Escherichia-Virus T4 (Gattung Tequatrovirus, Unterfamilie Tevenvirinae, Morphotyp Myoviren) wurde 1953 beobachtet.[63]
- Wie 1955 entdeckt wurde, ist N6-Methyladenin (6mA, m6A) in der DNA von Colibakterien vorhanden.[64]
- N6-Carbamoylmethyladenin wurde 1975 in den Bakteriophagen Mu (Spezies Escherichia-Virus Mu, wiss. Muvirus mu, mit Enterobacteria-Phage Mu, Morphotyp Myovirien) und Lambda-Mu[65][66] beschrieben.[67]
- 7-Methylguanin (m7G) wurde 1976 im Phagen DDVI („Enterobacteria phage DdVI“ alias „DdV1“, Gattung Tequatrovirus , früher T4virus) von Shigella disenteriae beschrieben.[68]
- N4-Methylcytosin (m4C) in DNA wurde 1983 beschrieben (in Bacillus centrosporus).[69]
- 1985 wurde 5-Hydroxycytosin im Genom des Rhizobium-Phagen RL38JI gefunden.[70]
- α-Putrescinylthymin (Alpha-Putrescinylthymin, putT) und α-Glutamylthymidin (Alpha-Glutamylthymidin) kommt im Genom sowohl des Delftia-Phagen ΦW-14 (Phi W-14, Spezies ‚Dellftia virus PhiW14‘, Gattung Ionavirus, Familie Myovriridae)[71] als auch des Bacillus-Phagen SP10 (Spezies „Bacillus phage SP-10“, Familie Herelleviridae, Morphotyp Siphoviren) vor.[72][73]
- 5-Dihydroxypentyluracil wurde im Bacillus-Phagen SP15 (auch SP-15, Spezies Bacillus-Virus SP15, wiss. Thornevirus SP15, Morphotyp Myoviren)[32][38] gefunden.[74]
Die Funktion dieser nicht-kanonischen Basen in der DNA ist nicht bekannt. Sie wirken zumindest teilweise als molekulares Immunsystem und helfen, die Bakterien vor einer Infektion durch Viren zu schützen.
Nicht-Standard und modifizierte Basen bei Mikroben sind aber noch nicht alles:
- Es wurde auch über vier Modifikationen der Cytosinreste in humaner DNA berichtet.[75] Diese Modifikationen bestehen aus dem Zusatz folgender Gruppen:
- Methyl (–CH3)
- Hydroxymethyl (–CH2OH)
- Formyl (–CHO)
- Carboxyl (–COOH)
Es wird angenommen, dass diese Modifikationen regulatorische Funktionen haben, Stichwort Epigenetik.
- Uracil ist in den Centromer-Regionen von mindestens zwei menschlichen Chromosomen (6 und 11) zu finden.[76]
Synthetische Basen
BearbeitenIm Labor wurde DNA (und auch RNA) mit weiteren künstlichen Basen versehen. Ziel ist es meist, damit unnatürliche Basenpaarungen (englisch unnatural base pairs, UBP) zu erzeugen:[77]
- Im Jahr 2004 wurde DNA erzeugt, die statt der vier Standardnukleobasen (A, T, G und C) ein erweitertes Alphabet mit sechs Nukleobasen (A, T, G, C, dP und dZ) enthielt. Dabei steht bei diesen zwei neuen Basen dP für 2-Amino-8-(1′-β-D-2′-desoxyribofuranosyl)-imidazo[1,2-a]-1,3,5-triazin-4(8H)-on und dZ für 6-Amino-5-nitro-3-(1′-β-D-2′-desoxyribofuranosyl)-2(1H)-pyridon.[78][79][80]
- Im Jahr 2006 wurden erstmals eine DNA mit um eine Benzolgruppe bzw. eine Naphthylgruppe erweiterten Basen untersucht (je nach Stellung der Erweiterungsgruppen entweder xDNA bzw. xxDNA oder yDNA bzw. yyDNA genannt).[81]
- Yorke Zhang et al. berichteten zur Jahreswende 2016/2017 über halbsynthetische Organismen mit einer DNA, die um die Basen X (alias NaM) und Y' (alias TPT3) bzw. die (Desoxyribo-)Nukleotide dX (dNaM) und dY' (dTPT3) erweitert wurde, die miteinander paaren. Vorausgegangen waren Versuche mit Paarungen auf Basis der Basen X und Y (alias 5SICS), d. h. der Nukleotiden dX und dY (alias d5SICS).[82][83] Weitere Basen, die mit 5SICS paaren können, sind FEMO und MMO2.[84]
- Anfang 2019 wurde über DNA und RNA mit jeweils acht Basen (vier natürliche und vier synthetische) berichtet, die sich alle paarweise einander zuordnen (Hachimoji-DNA).[85][86]
Enantiomere
BearbeitenDNA tritt in Lebewesen als D-DNA auf; L-DNA als Enantiomer (Spiegelmer) kann allerdings synthetisiert werden (gleiches gilt analog für RNA). L-DNA wird langsamer von Enzymen abgebaut als die natürliche Form, was sie für die Pharmaforschung interessant macht.[87][88]
Genetischer Informationsgehalt und Transkription
BearbeitenDNA-Moleküle spielen als Informationsträger und „Andockstelle“ eine wichtige Rolle für Enzyme, die für die Transkription zuständig sind. Weiterhin ist die Information bestimmter DNA-Abschnitte, wie sie etwa in operativen Einheiten wie dem Operon vorliegt, wichtig für Regulationsprozesse innerhalb der Zelle.
Bestimmte Abschnitte der DNA, die sogenannten Gene, codieren genetische Informationen, die Aufbau und Organisation des Organismus beeinflussen. Gene enthalten „Baupläne“ für Proteine oder Moleküle, die bei der Proteinsynthese oder der Regulation des Stoffwechsels einer Zelle beteiligt sind. Die Reihenfolge der Basen bestimmt dabei die genetische Information. Diese Basensequenz kann mittels Sequenzierung zum Beispiel über die Sanger-Methode ermittelt werden.
Die Basenabfolge (Basensequenz) eines Genabschnitts der DNA wird zunächst durch die Transkription in die komplementäre Basensequenz eines sogenannten Ribonukleinsäure-Moleküls überschrieben (abgekürzt RNA). RNA enthält im Unterschied zu DNA den Zucker Ribose anstelle von Desoxyribose und die Base Uracil anstelle von Thymin, der Informationsgehalt ist aber derselbe. Für die Proteinsynthese werden sogenannte mRNAs verwendet, einsträngige RNA-Moleküle, die aus dem Zellkern ins Cytoplasma hinaustransportiert werden, wo die Proteinsynthese stattfindet (siehe Proteinbiosynthese).
Nach der sog. „Ein-Gen-Ein-Protein-Hypothese“ wird von einem codierenden Abschnitt auf der DNA die Sequenz jeweils eines Proteinmoleküls abgelesen. Es gibt aber Regionen der DNA, die durch Verwendung unterschiedlicher Leseraster bei der Transkription jeweils mehrere Proteine codieren. Außerdem können durch alternatives Spleißen (nachträgliches Schneiden der mRNA) verschiedene Isoformen eines Proteins hergestellt werden.
Neben der codierenden DNA (den Genen) gibt es nichtcodierende DNA, die etwa beim Menschen über 90 Prozent der gesamten DNA einer Zelle ausmacht.
Die Speicherkapazität der DNA ist extrem hoch und konnte bisher nicht technisch nachgebildet werden. Die in einem Teelöffel getrockneter DNA enthaltene Information entspricht einer Größenordnung von einer Billion Compact Discs zu je 650 Megabyte.[89]
DNA-Replikation
BearbeitenDie DNA kann sich nach dem semikonservativen Prinzip mit Hilfe von Enzymen selbst verdoppeln (replizieren), sodass aus einem Doppelstrang zwei identische Doppelstränge werden. Die vorliegende doppelsträngige Helix muss dafür durch das Enzym Helikase aufgetrennt werden, nachdem sie von der Topoisomerase entspiralisiert wurde. Die entstehenden beiden Einzelstränge dienen jeweils als Matrize für die zwei zu synthetisierenden komplementären Gegenstränge. An die vorliegenden Einzelstränge können sich in Basenpaarung passende Nukleotide anlagern.
Die eigentliche DNA-Synthese, d. h. die Bindung der zu verknüpfenden Nukleotide, wird durch Enzyme aus der Gruppe der DNA-Polymerasen vollzogen. Ein zu verknüpfendes Nukleotid muss in der Triphosphat-Verbindung – also als Desoxyribonukleosidtriphosphat – vorliegen. Durch Abspaltung zweier Phosphatteile wird die für den Bindungsvorgang benötigte Energie frei.
Das Enzym Helikase trennt den entwundenen Doppelstrang auf und bildet so eine Replikationsgabel, zwei auseinander laufende DNA-Einzelstränge. In diesem Bereich markiert ein RNA-Primer, gebildet mit dem Enzym Primase, den Startpunkt der DNA-Neusynthese. An dieses RNA-Molekül hängt die DNA-Polymerase nacheinander Nukleotide, die denen der DNA-Einzelstränge komplementär entsprechen.
Die Verknüpfung von Nukleotiden zu einem DNA-Strang kann immer nur in 5'→3'-Richtung erfolgen. Entlang der Matrize des Leitstrangs, an dem alten 3'→5'-Strang, ist dies unterbrechungsfrei in Richtung der sich immer weiter öffnenden Replikationsgabel möglich.
Die Synthese entlang der Matrize des Folgestrangs, an dem alten 5'→3'-Strang, kann dagegen nicht kontinuierlich auf die Replikationsgabel zu verlaufen, sondern nur von dieser weg. Dabei ist der alte Doppelstrang zu Beginn der Replikation nur ein Stück weit geöffnet, sodass in Gegenrichtung nur ein kurzes Stück des neuen komplementären DNA-Strangs entstehen kann. Daher wird der komplementäre Strang stückweise synthetisiert, wobei die DNA-Polymerase jeweils nur etwa hundert bis tausend Nukleotide verknüpft. Hat sich die Replikationsgabel etwas weiter geöffnet, so wird ein neuer RNA-Primer an der Gabelung gebildet, der die DNA-Polymerase für das nächste Strangstück initiiert.
Bei der Synthese des neuen 3'→5'-Strangs wird deshalb pro DNA-Syntheseeinheit jeweils ein neuer RNA-Primer benötigt. Primer und zugehöriges DNA-Strangstück bezeichnet man als Okazaki-Fragment. Die einzelnen RNA-Primer werden anschließend wieder abgebaut. Die dadurch entstehenden Lücken im neuen DNA-Strang werden dann durch spezielle DNA-Polymerasen mit komplementären DNA-Nukleotiden ergänzt.
Zum Abschluss verknüpft das Enzym Ligase die noch nicht miteinander verbundenen neuen DNA-Strangabschnitte zu einem einzigen Strang.
Mutationen und andere DNA-Schäden
BearbeitenMutationen von DNA-Abschnitten – zum Beispiel Austausch von Basen gegen andere oder Änderungen in der Basensequenz – führen zu Veränderungen des Erbgutes, die zum Teil tödlich (letal) für den betroffenen Organismus sein können.
In seltenen Fällen sind solche Mutationen aber auch von Vorteil; sie bilden dann den Ausgangspunkt für die Veränderung von Lebewesen im Rahmen der Evolution. Mittels der Rekombination bei der geschlechtlichen Fortpflanzung wird diese Veränderung der DNA sogar zu einem entscheidenden Faktor bei der Evolution: Die eukaryotische Zelle besitzt in der Regel mehrere Chromosomensätze, d. h., ein DNA-Doppelstrang liegt mindestens zweimal vor. Durch wechselseitigen Austausch von Teilen dieser DNA-Stränge, das Crossing-over bei der Meiose, können so neue Eigenschaften entstehen.
DNA-Moleküle können durch verschiedene Einflüsse beschädigt werden. Ionisierende Strahlung, wie zum Beispiel UV- oder γ-Strahlung, Alkylierung sowie Oxidation können die DNA-Basen chemisch verändern oder zum Strangbruch führen. Diese chemischen Änderungen beeinträchtigen unter Umständen die Paarungseigenschaften der betroffenen Basen. Viele der Mutationen während der Replikation kommen so zustande.
Einige häufige DNA-Schäden sind:
- die Bildung von Uracil aus Cytosin unter spontanem Verlust einer Aminogruppe durch Hydrolyse: Uracil ist wie Thymin komplementär zu Adenin.
- Thymin-Thymin-Dimerschäden verursacht durch photochemische Reaktion zweier aufeinander folgender Thyminbasen im DNA-Strang durch UV-Strahlung, zum Beispiel aus Sonnenlicht. Diese Schäden sind wahrscheinlich eine wesentliche Ursache für die Entstehung von Hautkrebs.
- die Entstehung von 8-Oxoguanin durch Oxidation von Guanin: 8-Oxoguanin ist sowohl zu Cytosin als auch zu Adenin komplementär. Während der Replikation können beide Basen gegenüber 8-Oxoguanin eingebaut werden.
Aufgrund ihrer mutagenen Eigenschaften und ihres häufigen Auftretens (Schätzungen belaufen sich auf 104 bis 106 neue Schäden pro Zelle und Tag) müssen DNA-Schäden rechtzeitig aus dem Genom entfernt werden. Zellen verfügen dafür über ein effizientes DNA-Reparatursystem. Es beseitigt Schäden mit Hilfe folgender Strategien:
- Direkte Schadensreversion: Ein Enzym macht die chemische Änderung an der DNA-Base rückgängig.
- Basenexcisionsreparatur: Die fehlerhafte Base, zum Beispiel 8-Oxoguanin, wird aus dem Genom ausgeschnitten. Die entstandene freie Stelle wird anhand der Information im Gegenstrang neu synthetisiert.
- Nukleotidexcisionsreparatur: Ein größerer Teilstrang, der den Schaden enthält, wird aus dem Genom ausgeschnitten. Dieser wird anhand der Information im Gegenstrang neu synthetisiert.
- Homologe Rekombination: Sind beide DNA-Stränge beschädigt, wird die genetische Information aus dem zweiten Chromosom des homologen Chromosomenpaars für die Reparatur verwendet.
- Replikation mit speziellen Polymerasen: DNA-Polymerase η kann zum Beispiel fehlerfrei über einen TT-Dimerschaden replizieren. Menschen, bei denen Polymerase η nicht oder nur eingeschränkt funktioniert, leiden häufig an Xeroderma pigmentosum, einer Erbkrankheit, die zu extremer Sonnenlichtempfindlichkeit führt.
Denaturierung
BearbeitenDie Basenpaarung von DNA wird bei verschiedenen zellulären Vorgängen denaturiert. Die Basenpaarung wird dabei durch verschiedene DNA-bindende Proteine abschnittsweise aufgehoben, z. B. bei der Replikation oder der Transkription. Der Ort des Denaturierungsbeginns wird als Denaturierungsblase bezeichnet[90] und im Poland-Scheraga-Modell beschrieben.[91] Jedoch wird die DNA-Sequenz, die Steifigkeit und die Torsion nicht miteinbezogen.[92] Die Lebensdauer einer Denaturierungsblase beträgt zwischen einer Mikrosekunde und einer Millisekunde.[93]
Im Labor kann DNA durch physikalische und chemische Methoden denaturiert werden. DNA wird durch Formamid,[94] Dimethylformamid,[95] Guanidiniumsalze,[96] Natriumsalicylat,[95] Sulfoxid,[95] Dimethylsulfoxid (DMSO), verschiedene Alkohole,[95] Propylenglykol und Harnstoff[96] denaturiert, meist in Kombination mit Wärme. Auch konzentrierte Lösungen von Natriumhydroxid denaturieren DNA. Bei den chemischen Methoden erfolgt eine Absenkung der Schmelztemperatur der doppelsträngigen DNA.
DNA-Reinigung und Nachweis
BearbeitenDNA kann durch eine DNA-Reinigung, z. B. per DNA-Extraktion, von anderen Biomolekülen getrennt werden. Der qualitative Nachweis von DNA (welche DNA vorliegt) erfolgt meistens durch eine Polymerase-Kettenreaktion, eine isotherme DNA-Amplifikation, eine DNA-Sequenzierung, einen Southern Blot oder durch eine In-situ-Hybridisierung. Der quantitative Nachweis (wie viel DNA vorliegt) erfolgt meistens durch eine qPCR, bei gereinigten Proben mit nur einer DNA-Sequenz kann eine Konzentration auch durch Photometrie bei einer Wellenlänge von 260 nm gemessen werden. Eine Extinktion von 1 einer gereinigten DNA-Lösung entspricht bei doppelsträngiger DNA einer Konzentration von 50 µg/mL, bei einzelsträngiger DNA entspricht dies 33 µg/mL[97] und bei einzelsträngigen Oligonukleotiden liegt die Konzentration darunter, abhängig von der Zusammensetzung an Nukleinbasen (siehe DNA-Extraktion#Quantifizierung). Durch interkalierende Farbstoffe wie Ethidiumbromid, Propidiumiodid oder SYBR Green I sowie durch furchenbindende Farbstoffe wie DAPI, Pentamidine, Lexitropsine, Netropsin, Distamycin, Hoechst 33342 oder Hoechst 33258 kann DNA angefärbt werden. Weniger spezifisch gebundene DNA-Farbstoffe und Färbemethoden sind z. B. Methylenblau, der Carbocyanin-Farbstoff Stains-all oder die Silberfärbung. Durch Molecular Combing kann die DNA gestreckt und ausgerichtet werden.
„Alte“ DNA
BearbeitenAls aDNA („ancient DNA“; alte DNA) werden Reste von Erbgutmolekülen in toten Organismen bezeichnet, wenn keine direkten Verwandten des beprobten Organismus mehr leben. Auch wird die DNA des Menschen dann als aDNA bezeichnet, wenn das Individuum mindestens 75 Jahre vor der Probenuntersuchung verstorben ist.
Siehe auch
Bearbeiten- Xenonukleinsäure, XNA, dazu:
- LNA
- Peptid-Nukleinsäure (PNA)
- Morpholino
- Didesoxyribonukleosid-Triphosphate (ddNTPs): Artifizielle Zwischenstufen bei der DNA-Sequenzierung nach Sanger
- Desoxyadenosinmonoarsenat (dAMAs) siehe GFAJ-1 §Diskussion um den Einbau von Arsen in Biomoleküle (fraglicher Einbau in DNA bei Halomonas-Spezies GFAJ-1, siehe auch Halomonas titanicae)
Literatur
Bearbeiten- Chris R. Calladine und andere: DNA – Das Molekül und seine Funktionsweise. 3. Auflage. Spektrum Akademischer Verlag, Heidelberg 2005, ISBN 3-8274-1605-1.
- Ernst Peter Fischer: Am Anfang war die Doppelhelix. James D. Watson und die neue Wissenschaft vom Leben. Ullstein, Berlin 2004, ISBN 3-548-36673-2.
- Ernst Peter Fischer: Das Genom. Eine Einführung. Fischer, Frankfurt am Main 2002, ISBN 3-596-15362-X.
- James D. Watson: Die Doppelhelix. Rowohlt, Reinbek 1997, ISBN 3-499-60255-5.
- James D. Watson: Gene, Girls und Gamow. Erinnerungen eines Genies. Piper, München 2003, ISBN 3-492-04428-X.
- James D. Watson: Am Anfang war die Doppelhelix. Ullstein, Berlin 2003, ISBN 3-550-07566-9.
- James D. Watson, M. Gilman, J. Witkowski, M. Zoller: Rekombinierte DNA. 2. Auflage. Spektrum Akademischer Verlag, Heidelberg 1993, ISBN 3-86025-072-8.
- Tomas Lindahl: Instability and decay of the primary structure of DNA. In: Nature. Band 362, 1993, S. 709–715. doi:10.1038/362709a0.
- W. Wayt Gibbs: Preziosen im DNA-Schrott. In: Spektrum der Wissenschaft. Nr. 2, 2004, S. 68–75. (online)
- W. Wayt Gibbs: DNA ist nicht alles. In: Spektrum der Wissenschaft. Nr. 3, 2004, S. 68–75. (online)
- Hans-Jürgen Quadbeck-Seeger: Die Struktur der DNA – ein Modell-Projekt. In: Chemie in unserer Zeit. Band 42, 2008, S. 292–294. doi:10.1002/ciuz.200890046.
Weblinks
Bearbeiten- Literatur von und über Desoxyribonukleinsäure im Katalog der Deutschen Nationalbibliothek
- DNA-Isolierung aus Tomaten auf YouTube.
- DNA Interactive – Seite des Cold Spring Harbor Institute und des Howard Hughes Medical Institute (eine exzellente Einführung in die Thematik, engl.)
- DNA from the Beginning des Dolan DNA Learning Center
- „DNA from the Beginning“ (deutsch)
- „Übersetzer“ zum Finden der codierten Aminosäure zum codierenden Basentriplett oder umgekehrt
- „Übersetzer“ eines ganzen DNA-Abschnittes in die codierten Aminosäuren
- Harvard cracks DNA storage, crams 700 terabytes of data into a single gram
Anmerkungen und Einzelnachweise
Bearbeiten- ↑ Vgl. Duden. Die deutsche Rechtschreibung. Band 1. 26. Auflage. Mannheim 2013.
- ↑ Bärbel Häcker: DNS. In: Werner E. Gerabek, Bernhard D. Haage, Gundolf Keil, Wolfgang Wegner (Hrsg.): Enzyklopädie Medizingeschichte. De Gruyter, Berlin / New York 2005, ISBN 3-11-015714-4, S. 316 f.; hier: S. 316.
- ↑ Hubert Mania: Ein Opfer der wissenschaftlichen Vorurteile seiner Zeit. Die DNS wurde bereits 1869 im Tübinger Renaissanceschloss entdeckt. Auf: Telepolis. 17. April 2004.
- ↑ Johann Friedrich Miescher: Brief an Wilhelm His, 17. Dezember 1892 In: Miescher, Johann Friedrich: Die histochemischen und physiologischen Arbeiten, Band 1, Seite 116 f. (Dieser Brief wurde erst 1897 nach dem Tode Friedrich Mieschers publiziert.)
- ↑ Vgl. auch: Hans Blumenberg: Die Lesbarkeit der Welt. Frankfurt am Main 1986. Suhrkamp Verlag. Kapitel XXII Der genetische Code und seine Leser. Seite 372 ff. Dort eine Darstellung der Bedeutung Friedrich Mieschers in Hinsicht auf die Einführung des Schriftvergleichs für die Erbinformation.
- ↑ Richard Altmann: Ueber Nucleinsäuren. In: Archiv für Anatomie und Physiologie. Physiologische Abteilung. Leipzig 1889, S. 524–536.
- ↑ P.A. Levene: The structure of yeast nucleic acid. In: Journal of Biological Chemistry. Band 40, Nr. 2, Dezember 1919, S. 415–424, doi:10.1016/s0021-9258(18)87254-4.
- ↑ Joachim Gerlach: Hartwig Kuhlenbeck† In: Würzburger medizinhistorische Mitteilungen. Band 2, 1984, S. 269–273, hier: S. 271.
- ↑ W. Astbury: Nucleic acid. In: Symp. SOC. Exp. Bbl. Band 1, Nr. 66, 1947.
- ↑ O. Avery, C. MacLeod, M. McCarty: Studies on the chemical nature of the substance inducing transformation of pneumococcal types. Inductions of transformation by a desoxyribonucleic acid fraction isolated from pneumococcus type III. In: J Exp Med. Band 79, Nr. 2, 1944, S. 137–158, doi:10.1084/jem.149.2.297.
- ↑ A. Hershey, M. Chase: Independent functions of viral protein and nucleic acid in growth of bacteriophage. In: J Gen Physiol. Band 36, Nr. 1, 1952, S. 39–56, doi:10.1085/jgp.36.1.39, PMID 12981234.
- ↑ 50 Jahre Doppelhelix. Spektrum der Wissenschaft, 28. Februar 2003
- ↑ February 28: The Day Scientists Discovered the Double Helix. Scientific American, 28. Februar 2013.
- ↑ a b J. D. Watson, F. H. Crick: Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid. In: Nature. Band 171, Nr. 4356, 25. April 1953, S. 737–738, doi:10.1038/171737a0, PMID 13054692.
- ↑ Siegfried Wendt (Universität Potsdam) berichtet: "Ich habe Erwin Chargaff in seinen letzten Lebensjahren persönlich kennengelernt und weiß, wie sehr es ihn gekränkt hat, dass alle Welt Crick und Watson als die Entdecker der DNA-Struktur feiert und sein Name heute kaum noch fällt": In: Forschung und Lehre 3/24: Leserforum, S. 198.
- ↑ Moritz Aisslinger: Sie war’s. Untertitel: Anfang der Fünfzigerjahre: Die Forscherin Rosalind Franklin kommt dem Geheimnis des Lebens ganz nahe. Doch drei Männer betrügen sie um den Lohn ihrer Arbeit – und erhalten den Nobelpreis. In: Die Zeit Nr. 42 vom 13. Oktober 2022, S. 15–17 (Mit Aktualisierungen in der online-Version am 16.10. Komplettansicht des Artikels hinter der Bezahlschranke.). In der Artikel-Reihe: Sternstunden der Menschheit. (Mit 2 Fotos von ihr aus den 1950ern und einer Kopie des photo 51 von 2. Mai 1952)
- ↑ DNA-Entdeckung beruht auf Ideendiebstahl: Die Väter sind eine Mutter, taz die Tageszeitung, 24. April 2023.
- ↑ Katharina Kramer: Dem Leben auf der Spur. In: GEO kompakt. Nr. 7, 2006.
- ↑ Informationen der Nobelstiftung zur Preisverleihung 1962.
- ↑ www.ensembl.org, Homo sapiens: Datenbankstand von Februar 2009. (Website auf Englisch).
- ↑ R. Wing, H. Drew, T. Takano, C. Broka, S. Tanaka, K. Itakura, R. Dickerson: Crystal structure analysis of a complete turn of B-DNA. In: Nature. Band 287, Nr. 5784, 1980, S. 755–758, PMID 7432492.
- ↑ C. Pabo, R. Sauer: Protein-DNA recognition. In: Annu Rev Biochem. Band 53, S. 293–321, PMID 6236744.
- ↑ S. C. Ha, K. Lowenhaupt, A. Rich, Y. G. Kim, K. K. Kim: Crystal structure of a junction between B-DNA and Z-DNA reveals two extruded bases. In: Nature. Band 437, 2005, S. 1183–1186, PMID 16237447.
- ↑ a b Peter Yakovchuk, Ekaterina Protozanova, Maxim D. Frank-Kamenetskii: Base-stacking and base-pairing contributions into thermal stability of the DNA double helix. In: Nucleic Acids Research. Band 34, Nr. 2, 2006, S. 564–574. doi:10.1093/nar/gkj454 PMID 16449200
- ↑ Gerhard Steger (Hrsg.): Bioinformatik: Methoden zur Vorhersage von RNA- und Proteinstrukturen. Birkhäuser Verlag, Basel, Boston, Berlin 2003.
- ↑ S. Kiljunen, K. Hakala, E. Pinta, S. Huttunen, P. Pluta, A. Gador, H. Lönnberg, M. Skurnik: Yersiniophage phiR1-37 is a tailed bacteriophage having a 270 kb DNA genome with thymidine replaced by deoxyuridine. In: Microbiology. 151. Jahrgang, Pt 12, Dezember 2005, S. 4093–4102, doi:10.1099/mic.0.28265-0, PMID 16339954.
- ↑ J. Uchiyama, I. Takemura-Uchiyama, Y. Sakaguchi, K. Gamoh, S. Kato, M. Daibata, T. Ujihara, N. Misawa, S. Matsuzaki: Intragenus generalized transduction in Staphylococcus spp. by a novel giant phage. In: The ISME Journal. 8. Jahrgang, Nr. 9, September 2014, S. 1949–1952, doi:10.1038/ismej.2014.29, PMID 24599069, PMC 4139722 (freier Volltext).
- ↑ Taxonomy - Bacillus phage PBS2 (Bacteriophage PBS2) (SPECIES), auf UniProt, abgerufen am 21. Februar 2019.
- ↑ Yersinia phage phiR1-RT, auf: Virus-Host DB.
- ↑ P. Molnár, L. Marton, R. Izrael, H. L. Pálinkás, B. G. Vértessy: Uracil moieties in Plasmodium falciparum genomic DNA. FEBS Open Bio, Band 8, Nr. 11, 2018, S. 1763–1772.
- ↑ Andrew M. Q. King et al. (Hrsg.): Virus Taxonomy: Classification and Nomenclature of Viruses (PDF; 10 MB) Ninth Report of the International Committee on Taxonomy of Viruses
- ↑ a b c ICTV: dsDNA Viruses > Myoviridae ( vom 26. Dezember 2018 im Internet Archive), in: ICTV 9th Report (2011)
- ↑ a b E. Casella, O. Markewych, M. Dosmar, H. Witmer: Production and expression of dTMP-enriched DNA of bacteriophage SP15. In: Journal of Virology. Band 28, Nr. 3, Dezember 1978, S. 753–766, doi:10.1128/JVI.28.3.753-766.1978, PMID 153409.
- ↑ David H. Roscoe: Synthesis of DNA in phage-infected Bacillus subtilis, in: Virology 38(4), September 1969, S. 527–537, doi:10.1016/0042-6822(69)90173-1.
- ↑ Bacillus phage SP-15, auf: Virus-Host DB
- ↑ M. S. Walker, M. Mandel: Biosynthesis of 5-(4'5'-dihydroxypentyl) uracil as a nucleoside triphosphate in bacteriophage SP15-infected Bacillus subtilis. In: Journal of Virology. Band 25, Nr. 2, Februar 1978, S. 500–509, doi:10.1128/JVI.25.2.500-509.1978, PMID 146749.
- ↑ J. Marmurm et al.: Unique Properties of Nucleic Acid from Bacillus subtilis Phage SP-15. In: Nature New Biology, 1972, 239, S. 68. doi:10.1038/newbio239068a0 – SP-15 infiziert B. subtilis und B. licheniformis.
- ↑ a b c Andrew M. Kropinski et al.: The Sequence of Two Bacteriophages with Hypermodified Bases Reveals Novel Phage-Host Interactions. In: Viruses, Mai 2018, 10(5), S. 217. PMC 5977210 (freier Volltext), PMID 29695085, PMC 5977210 (freier Volltext).
- ↑ L Simpson: A base called J. In: Proceedings of the National Academy of Sciences of the United States of America. 95. Jahrgang, Nr. 5, März 1998, S. 2037–2038, doi:10.1073/pnas.95.5.2037, PMID 9482833, PMC 33841 (freier Volltext), bibcode:1998PNAS...95.2037S.
- ↑ P Borst, R Sabatini: Base J: discovery, biosynthesis, and possible functions. In: Annual Review of Microbiology. 62. Jahrgang, 2008, S. 235–251, doi:10.1146/annurev.micro.62.081307.162750, PMID 18729733.
- ↑ M Cross, R Kieft, R Sabatini, M Wilm, M de Kort, GA van der Marel, JH van Boom, F van Leeuwen, P Borst: The modified base J is the target for a novel DNA-binding protein in kinetoplastid protozoans. In: The EMBO Journal. 18. Jahrgang, Nr. 22, November 1999, S. 6573–6581, doi:10.1093/emboj/18.22.6573, PMID 10562569, PMC 1171720 (freier Volltext).
- ↑ C DiPaolo, R Kieft, M Cross, R Sabatini: Regulation of trypanosome DNA glycosylation by a SWI2/SNF2-like protein. In: Molecular Cell. 17. Jahrgang, Nr. 3, Februar 2005, S. 441–451, doi:10.1016/j.molcel.2004.12.022, PMID 15694344.
- ↑ S Vainio, PA Genest, B ter Riet, H van Luenen, P Borst: Evidence that J-binding protein 2 is a thymidine hydroxylase catalyzing the first step in the biosynthesis of DNA base J. In: Molecular and Biochemical Parasitology. 164. Jahrgang, Nr. 2, April 2009, S. 157–161, doi:10.1016/j.molbiopara.2008.12.001, PMID 19114062.
- ↑ LM Iyer, M Tahiliani, A Rao, L Aravind: Prediction of novel families of enzymes involved in oxidative and other complex modifications of bases in nucleic acids. In: Cell Cycle. 8. Jahrgang, Nr. 11, Juni 2009, S. 1698–1710, doi:10.4161/cc.8.11.8580, PMID 19411852, PMC 2995806 (freier Volltext).
- ↑ HG van Luenen, C Farris, S Jan, PA Genest, P Tripathi, A Velds, RM Kerkhoven, M Nieuwland, A Haydock, G Ramasamy, S Vainio, T Heidebrecht, A Perrakis, L Pagie, B van Steensel, PJ Myler, P Borst: Glucosylated hydroxymethyluracil, DNA base J, prevents transcriptional readthrough in Leishmania. In: Cell. 150. Jahrgang, Nr. 5, August 2012, S. 909–921, doi:10.1016/j.cell.2012.07.030, PMID 22939620, PMC 3684241 (freier Volltext).
- ↑ DZ Hazelbaker, S Buratowski: Transcription: base J blocks the way. In: Current Biology. 22. Jahrgang, Nr. 22, November 2012, S. R960–2, doi:10.1016/j.cub.2012.10.010, PMID 23174300, PMC 3648658 (freier Volltext).
- ↑ NCBI: Cyanophage S-2L (species)
- ↑ Patentanmeldung WO03093461A2: Genomic Library of Cyanophages S-2L and functional Analysis. Angemeldet am 28. April 2003, veröffentlicht am 13. November 2003, Anmelder: Pasteur Institut et al, Erfinder: Philippe Marliere et al.
- ↑ Han Xia et al.: Freshwater cyanophages. In: Virologica Sinica, Band 28, Nr. 5, S. 253–259, Oktober 2013, doi:10.1007/s12250-013-3370-1
- ↑ M. H. V. van Regenmortel et al.: ICTV 7th Report ( vom 24. Februar 2021 im Internet Archive) (PDF; 857 kB) 2000
- ↑ R. S. Safferman, R. E. Cannon, P. R. Desjardins, B. V. Gromov, R. Haselkorn, L. A. Sherman, M. Shilo: Classification and Nomenclature of Viruses of Cyanobacteria. In: Intervirology. 19. Jahrgang, Nr. 2, 1983, S. 61–66, doi:10.1159/000149339, PMID 6408019.
- ↑ Roger Hull, Fred Brown, Chris Payne (Hrsg.): Virology: A Directory and Dictionary of Animal, Bacterial and Plant Viruses, Macmillan Reference Books, ISBN 978-1-349-07947-6, doi:10.1007/978-1-349-07945-2, Treffer
- ↑ IY Khudyakov, MD Kirnos, NI Alexandrushkina, BF Vanyushin: Cyanophage S-2L contains DNA with 2,6-diaminopurine substituted for adenine. In: Virology. 88. Jahrgang, Nr. 1, 1978, S. 8–18, PMID 676082.
- ↑ Jacinta Bowler: Some Viruses Have a Completely Different Genome to The Rest of Life on Earth, auf: sciencealert vom 4. Mai 2021
- ↑ NCBI: Acinetobacter phage SH-Ab 15497 (species)
- ↑ Tina Hesman Saey: Some viruses thwart bacterial defenses with a unique genetic alphabet, auf: ScienceNews vom 5. Mai 2021
- ↑ JJ Thiaville, SM Kellner, Y Yuan, G Hutinet, PC Thiaville, W Jumpathong, S Mohapatra, C Brochier-Armanet, AV Letarov, R Hillebrand, CK Malik, CJ Rizzo, PC Dedon, V de Crécy-Lagard: Novel genomic island modifies DNA with 7-deazaguanine derivatives. In: Proceedings of the National Academy of Sciences of the United States of America. 113. Jahrgang, Nr. 11, 2016, S. E1452–1459, doi:10.1073/pnas.1518570113, PMID 26929322, PMC 4801273 (freier Volltext), bibcode:2016PNAS..113E1452T.
- ↑ NCBI: Enterobacteria phage 9g (no rank)
- ↑ TB Johnson, RD Coghill: Pyrimidines. CIII. The discovery of 5-methylcytosine in tuberculinic acid, the nucleic acid of the tubercle bacillus. In: Journal of the American Chemical Society. 47. Jahrgang, 1925, S. 2838–2844.
- ↑ Pieter-Jan Ceyssens: The Genome and Structural Proteome of YuA, a New Pseudomonas aeruginosa Phage Resembling M6. In: Journal of Bacteriology. 190(4): S. 1429–1435, März 2008, doi:10.1128/JB.01441-07.
- ↑ Tsong-teh Kuo, Tan-chi Huang, Mei-hui Teng: 5-Methylcytosine replacing cytosine in the deoxyribonucleic acid of a bacteriophage for Xanthomonas oryzae. In: Journal of Molecular Biology. 34. Jahrgang, Nr. 2, Juli 1968, S. 373–375, doi:10.1016/0022-2836(68)90263-5, PMID 5760463.
- ↑ Heike Vogelsang-Wenke, Dieter Oesterhelt: Isolation of a halobacterial phage with a fully cytosine-methylated genome. In: MGG Molecular & General Genetics. 211. Jahrgang, Nr. 3, März 1988, S. 407–414, doi:10.1007/BF00425693.
- ↑ GR Wyatt, SS Cohen: The bases of the nucleic acids of some bacterial and animal viruses: the occurrence of 5-hydroxymethylcytosine. In: The Biochemical Journal. 55. Jahrgang, Nr. 5, 1953, S. 774–782, PMID 13115372, PMC 1269533 (freier Volltext).
- ↑ DB Dunn, JD Smith: Occurrence of a new base in the deoxyribonucleic acid of a strain of Bacterium coli. In: Nature. 175. Jahrgang, Nr. 4451, 1955, S. 336–337, PMID 13235889.
- ↑ E Bremer et al.: Lambda placMu: a transposable derivative of bacteriophage lambda for creating lacZ protein fusions in a single step. In: J Bacteriol. Band 158, Nr. 3, Juni 1984, S. 1084–1093, PMC 215554 (freier Volltext), PMID 6327627
- ↑ Diego de Mendoza, Alberto L. Rosa: Cloning of mini-Mu bacteriophage in cosmids: in vivo packaging into phage lambda heads. In: Gene. Band 39, Nr. 1, 1985, S. 55–59, doi:10.1016/0378-1119(85)90107-6.
- ↑ B. Allet, A. I. Bukhari: Analysis of bacteriophage mu and lambda-mu hybrid DNAs by specific endonucleases. In: Journal of Molecular Biology. 92. Jahrgang, Nr. 4, 1975, S. 529–540, PMID 1097703.
- ↑ II Nikolskaya, NG Lopatina, SS Debov: Methylated guanine derivative as a minor base in the DNA of phage DDVI Shigella disenteriae. In: Biochimica et Biophysica Acta. 435. Jahrgang, Nr. 2, 1976, S. 206–210, PMID 779843.
- ↑ A Janulaitis, S Klimasauskas, M Petrusyte, V Butkus: Cytosine modification in DNA by BcnI methylase yields N4-methylcytosine. In: FEBS Letters. 161. Jahrgang, Nr. 1, 1983, S. 131–134, PMID 6884523.
- ↑ D Swinton, S Hattman, R Benzinger, V Buchanan-Wollaston, J Beringer: Replacement of the deoxycytidine residues in Rhizobium bacteriophage RL38JI DNA. In: FEBS Letters. 184. Jahrgang, Nr. 2, 1985, S. 294–298, PMID 2987032.
- ↑ Ionavirus (Seite nicht mehr abrufbar, festgestellt im Dezember 2023. Suche in Webarchiven), ICTV Proposals
- ↑ KL Maltman, J Neuhard, RA Warren: 5-[(Hydroxymethyl)-O-pyrophosphoryl]uracil, an intermediate in the biosynthesis of alpha-putrescinylthymine in deoxyribonucleic acid of bacteriophage phi W-14. In: Biochemistry. 20. Jahrgang, Nr. 12, 1981, S. 3586–3591, PMID 7260058.
- ↑ YJ Lee, N Dai, SE Walsh, S Müller, ME Fraser, KM Kauffman, C Guan, IR Corrêa Jr, PR Weigele: Identification and biosynthesis of thymidine hypermodifications in the genomic DNA of widespread bacterial viruses. In: Proc Natl Acad Sci USA, 3. April 2018, 115(14), S. E3116–E3125. doi:10.1073/pnas.1714812115, PMID 29555775.
- ↑ H. Hayashi, K. Nakanishi, C. Brandon, J. Marmur: Structure and synthesis of dihydroxypentyluracil from bacteriophage SP-15 deoxyribonucleic acid. In: J. Am. Chem. Soc., 1973, 95, S. 8749–8757. doi:10.1021/ja00807a041.
- ↑ T Carell, MQ Kurz, M Müller, M Rossa, F Spada: Non-canonical bases in the genome: The regulatory information layer in DNA. In: Angewandte Chemie (International Ed. in English). 2017, doi:10.1002/anie.201708228, PMID 28941008.
- ↑ X Shu, M Liu, Z Lu, C Zhu, H Meng, S Huang, X Zhang, C Yi: Genome-wide mapping reveals that deoxyuridine is enriched in the human centromeric DNA. In: Nat Chem Biol, 2018, doi:10.1038/s41589-018-0065-9.
- ↑ Kyung Hyun Lee, Kiyofumi Hamashima, Michiko Kimoto, Ichiro Hirao: Genetic alphabet expansion biotechnology by creating unnatural base pairs. In: Current Opinion in Biotechnology, Volume 51, Juni 2018, S. 8–15, ScienceDirect, ResearchGate, PMID 29049900, doi:10.1016/j.copbio
- ↑ A. M. Sismour, S. Lutz, J. H. Park, M. J. Lutz, P. L. Boyer, S. H. Hughes, S. A. Benner: PCR amplification of DNA containing non-standard base pairs by variants of reverse transcriptase from Human Immunodeficiency Virus-1. In: Nucleic Acids Research. Band 32, Nummer 2, 2004, S. 728–735, doi:10.1093/nar/gkh241, PMID 14757837, PMC 373358 (freier Volltext).
- ↑ Z. Yang, D. Hutter, P. Sheng, A. M. Sismour und S. A. Benner: Artificially expanded genetic information system: a new base pair with an alternative hydrogen bonding pattern. In: Nucleic Acids Res., 34, 2006, S. 6095–6101. PMC 1635279 (freier Volltext)
- ↑ Z. Yang, A. M. Sismour, P. Sheng, N. L. Puskar, S. A. Benner: Enzymatic incorporation of a third nucleobase pair. In: Nucleic Acids Research, Band 35, Nummer 13, 2007, S. 4238–4249,
doi:10.1093/nar/gkm395, PMID 17576683, PMC 1934989 (freier Volltext). - ↑ S. R. Lynch, H. Liu, J. Gao, E. T. Kool: Toward a designed, functioning genetic system with expanded-size base pairs: solution structure of the eight-base xDNA double helix. In: Journal of the American Chemical Society, Band 128, Nr. 45, November 2006, S. 14704–14711,
doi:10.1021/ja065606n. PMID 17090058. PMC 2519095 (freier Volltext). - ↑ Yorke Zhang, Brian M. Lamb, Aaron W. Feldman, Anne Xiaozhou Zhou, Thomas Lavergne, Lingjun Li, Floyd E. Romesberg: A semisynthetic organism engineered for the stable expansion of the genetic alphabet. In: PNAS, 114 (6), 7. Februar 2017, S. 1317–1322; first published January 23, 2017, doi:10.1073/pnas.1616443114, Hrsg.: Clyde A. Hutchison III, The J. Craig Venter Institute
- ↑ Forscher züchten „Frankenstein“-Mikrobe. Auf: scinexx, 24. Januar 2017
- ↑ Indu Negi, Preetleen Kathuria, Purshotam Sharma, Stacey D. Wetmore: How do hydrophobic nucleobases differ from natural DNA nucleobases? Comparison of structural features and duplex properties from QM calculations and MD simulations. In: Phys. Chem. Chem. Phys., 2017, 19, S. 16305–16374, doi:10.1039/C7CP02576A.
- ↑ Shuichi Hoshika, Nicole A. Leal, Myong-Jung Kim, Myong-Sang Kim, Nilesh B. Karalkar, Hyo-Joong Kim, Alison M. Bates, Norman E. Watkins Jr., Holly A. SantaLucia, Adam J. Meyer, Saurja DasGupta, Joseph A. Piccirilli, Andrew D. Ellington, John SantaLucia Jr., Millie M. Georgiadis, Steven A. Benner: Hachimoji DNA and RNA: A genetic system with eight building blocks. In: Science, 363 (6429), 22. Februar 2019, S. 884–887, doi:10.1126/science.aat0971.
- ↑ Daniela Albat: DNA mit acht Buchstaben. scinexx. Erweiterter Code des Lebens. Auf: wissenschaft.de (bdw online), beide vom 22. Februar 2019.
- ↑ W. Purschke, F. Radtke, F. Kleinjung, S. Klussmann: A DNA Spiegelmer to staphylococcal enterotoxin B. In: Nucleic Acids Research. Band 31, Nr. 12, 2003, S. 3027–3032. doi:10.1093/nar/gkg413, PMID 12799428.
- ↑ Gosuke Hayashi, Masaki Hagihara, Kazuhiko Nakatani: Application of L-DNA as a molecular tag. In: Nucleic Acids Symposium Series, Band 49, Nr. 1, 2005, S. 261–262. doi:10.1093/nass/49.1.261, PMID 17150733.
- ↑ Leonard M. Adelmann: Rechnen mit der DNA. In: Spektrum der Wissenschaft. November 1998, S. 77, (Volltext)
- ↑ François Sicard, Nicolas Destainville, Manoel Manghi: DNA denaturation bubbles: Free-energy landscape and nucleation/closure rates. In: The Journal of Chemical Physics. 142. Jahrgang, Nr. 3, 21. Januar 2015, S. 034903, doi:10.1063/1.4905668, arxiv:1405.3867.
- ↑ Simon Lieu: The Poland-Scheraga Model. (2015): 0-5. Massachusetts Institute of Technology, 14. Mai 2015.
- ↑ C. Richard, A. J. Guttmann: Poland–Scheraga Models and the DNA Denaturation Transition. In: Journal of Statistical Physics. 115, 2004, S. 925, doi:10.1023/B:JOSS.0000022370.48118.8b.
- ↑ Grégoire Altan-Bonnet, Albert Libchaber, Oleg Krichevsky: Bubble Dynamics in Double-Stranded DNA. In: Physical Review Letters. 90. Jahrgang, Nr. 13, 1. April 2003, doi:10.1103/physrevlett.90.138101.
- ↑ J. Marmur, P. O. Ts'O: Denaturation of deoxyribonucleic acid by formamide. In: Biochimica et Biophysica Acta. Band 51, Juli 1961, S. 32–36, PMID 13767022.
- ↑ a b c d Prog Nucleic Acid Res&Molecular Bio. Academic Press, 1963, ISBN 978-0-08-086289-7, S. 267.
- ↑ a b Hyone-Myong Eun: Enzymology Primer for Recombinant DNA Technology. Elsevier, 1996, ISBN 978-0-08-053113-7, S. 67.
- ↑ Wolfgang Hennig: Genetik. Springer-Verlag, 2013, ISBN 978-3-662-07430-5 (eingeschränkte Vorschau in der Google-Buchsuche).